 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLlamaRec-LKG-RAG: A Single-Pass, Learnable Knowledge Graph-RAG Framework for LLM-Based Ranking
Jun 09, 2025Recent advances in Large Language Models (LLMs) have driven their adoption in recommender systems through Retrieval-Augmented Generation (RAG) frameworks. However, existing RAG approaches predominantly rely on flat, similarity-based retrieval that fails to leverage the rich relational structure inherent in user-item interactions. We introduce LlamaRec-LKG-RAG, a novel single-pass, end-to-end trainable framework that integrates personalized knowledge graph context into LLM-based recommendation ranking. Our approach extends the LlamaRec architecture by incorporating a lightweight user preference module that dynamically identifies salient relation paths within a heterogeneous knowledge graph constructed from user behavior and item metadata. These personalized subgraphs are seamlessly integrated into prompts for a fine-tuned Llama-2 model, enabling efficient and interpretable recommendations through a unified inference step. Comprehensive experiments on ML-100K and Amazon Beauty datasets demonstrate consistent and significant improvements over LlamaRec across key ranking metrics (MRR, NDCG, Recall). LlamaRec-LKG-RAG demonstrates the critical value of structured reasoning in LLM-based recommendations and establishes a foundation for scalable, knowledge-aware personalization in next-generation recommender systems. Code is available at~\href{https://github.com/VahidAz/LlamaRec-LKG-RAG}{repository}.
MiniGPT-Reverse-Designing: Predicting Image Adjustments Utilizing MiniGPT-4
Jun 03, 2024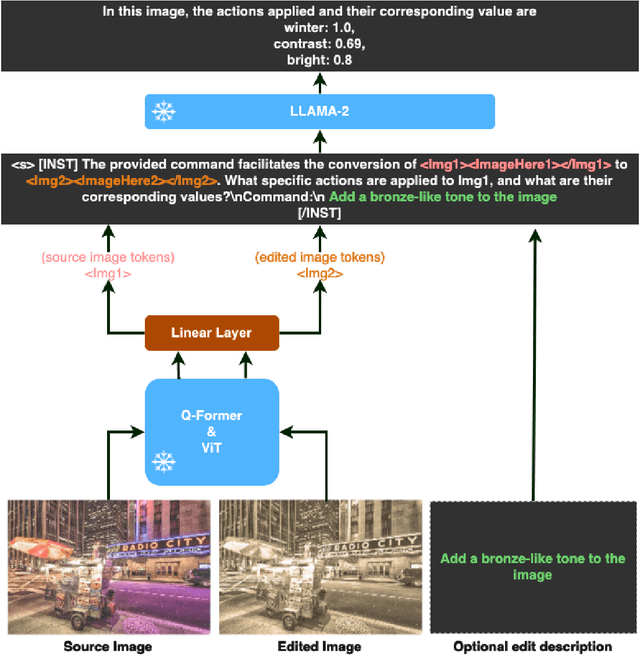



Vision-Language Models (VLMs) have recently seen significant advancements through integrating with Large Language Models (LLMs). The VLMs, which process image and text modalities simultaneously, have demonstrated the ability to learn and understand the interaction between images and texts across various multi-modal tasks. Reverse designing, which could be defined as a complex vision-language task, aims to predict the edits and their parameters, given a source image, an edited version, and an optional high-level textual edit description. This task requires VLMs to comprehend the interplay between the source image, the edited version, and the optional textual context simultaneously, going beyond traditional vision-language tasks. In this paper, we extend and fine-tune MiniGPT-4 for the reverse designing task. Our experiments demonstrate the extensibility of off-the-shelf VLMs, specifically MiniGPT-4, for more complex tasks such as reverse designing. Code is available at this \href{https://github.com/VahidAz/MiniGPT-Reverse-Designing}