 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePack and Measure: An Effective Approach for Influence Propagation in Social Networks
Dec 31, 2023The Influence Maximization problem under the Independent Cascade model (IC) is considered. The problem asks for a minimal set of vertices to serve as "seed set" from which a maximum influence propagation is expected. New seed-set selection methods are introduced based on the notions of a $d$-packing and vertex centrality. In particular, we focus on selecting seed-vertices that are far apart and whose influence-values are the highest in their local communities. Our best results are achieved via an initial computation of a $d$-Packing followed by selecting either vertices of high degree or high centrality in their respective closed neighborhoods. This overall "Pack and Measure" approach proves highly effective as a seed selection method.
Graph Minors Meet Machine Learning: the Power of Obstructions
Jun 08, 2020
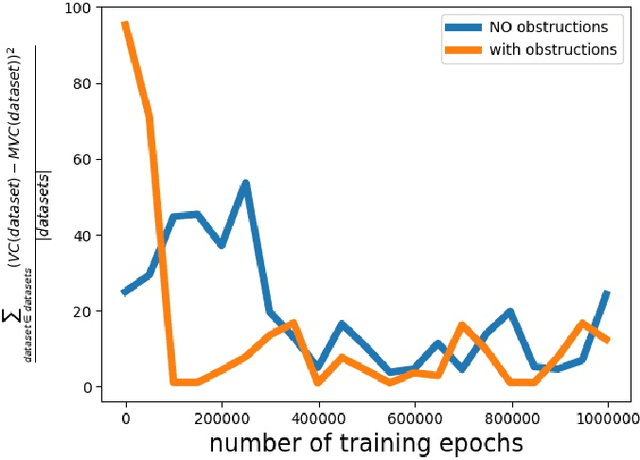
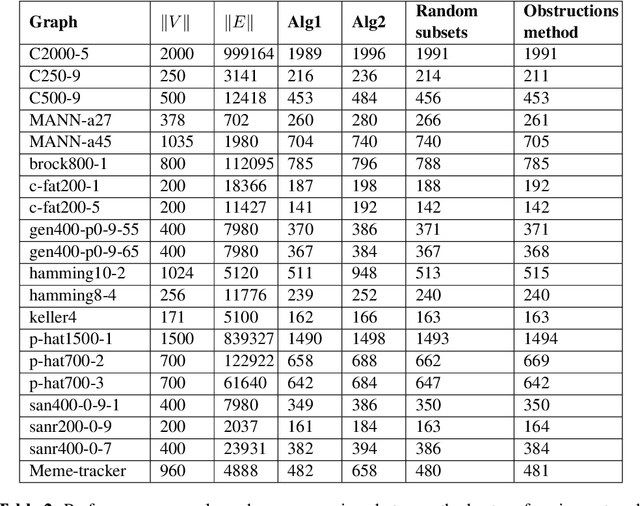
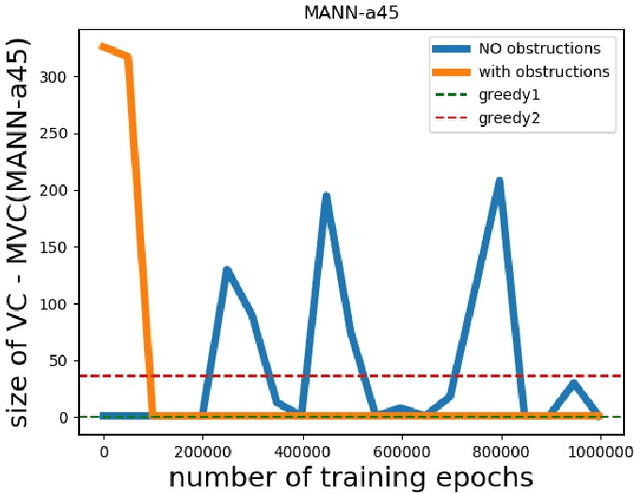
Computational intractability has for decades motivated the development of a plethora of methodologies that mainly aimed at a quality-time trade-off. The use of Machine Learning techniques has finally emerged as one of the possible tools to obtain approximate solutions to ${\cal NP}$-hard combinatorial optimization problems. In a recent article, Dai et al. introduced a method for computing such approximate solutions for instances of the Vertex Cover problem. In this paper we consider the effectiveness of selecting a proper training strategy by considering special problem instances called "obstructions" that we believe carry some intrinsic properties of the problem itself. Capitalizing on the recent work of Dai et al. on the Vertex Cover problem, and using the same case study as well as 19 other problem instances, we show the utility of using obstructions for training neural networks. Experiments show that training with obstructions results in a huge reduction in number of iterations needed for convergence, thus gaining a substantial reduction in the time needed for training the model.
Concise Fuzzy Representation of Big Graphs: a Dimensionality Reduction Approach
Mar 08, 2018The enormous amount of data to be represented using large graphs exceeds in some cases the resources of a conventional computer. Edges in particular can take up a considerable amount of memory as compared to the number of nodes. However, rigorous edge storage might not always be essential to be able to draw the needed conclusions. A similar problem takes records with many variables and attempts to extract the most discernible features. It is said that the "dimension" of this data is reduced. Following an approach with the same objective in mind, we can map a graph representation to a k-dimensional space and answer queries of neighboring nodes by measuring Euclidean distances. The accuracy of our answers would decrease but would be compensated for by fuzzy logic which gives an idea about the likelihood of error. This method allows for reasonable representation in memory while maintaining a fair amount of useful information. Promising preliminary results are obtained and reported by testing the proposed approach on a number of Facebook graphs.