 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding and Diagnosing Deep Reinforcement Learning
Jun 23, 2024Deep neural policies have recently been installed in a diverse range of settings, from biotechnology to automated financial systems. However, the utilization of deep neural networks to approximate the value function leads to concerns on the decision boundary stability, in particular, with regard to the sensitivity of policy decision making to indiscernible, non-robust features due to highly non-convex and complex deep neural manifolds. These concerns constitute an obstruction to understanding the reasoning made by deep neural policies, and their foundational limitations. Hence, it is crucial to develop techniques that aim to understand the sensitivities in the learnt representations of neural network policies. To achieve this we introduce a theoretically founded method that provides a systematic analysis of the unstable directions in the deep neural policy decision boundary across both time and space. Through experiments in the Arcade Learning Environment (ALE), we demonstrate the effectiveness of our technique for identifying correlated directions of instability, and for measuring how sample shifts remold the set of sensitive directions in the neural policy landscape. Most importantly, we demonstrate that state-of-the-art robust training techniques yield learning of disjoint unstable directions, with dramatically larger oscillations over time, when compared to standard training. We believe our results reveal the fundamental properties of the decision process made by reinforcement learning policies, and can help in constructing reliable and robust deep neural policies.
A Survey Analyzing Generalization in Deep Reinforcement Learning
Jan 04, 2024



Reinforcement learning research obtained significant success and attention with the utilization of deep neural networks to solve problems in high dimensional state or action spaces. While deep reinforcement learning policies are currently being deployed in many different fields from medical applications to self driving vehicles, there are still ongoing questions the field is trying to answer on the generalization capabilities of deep reinforcement learning policies. In this paper, we will outline the fundamental reasons why deep reinforcement learning policies encounter overfitting problems that limit their robustness and generalization capabilities. Furthermore, we will formalize and unify the diverse solution approaches to increase generalization, and overcome overfitting in state-action value functions. We believe our study can provide a compact systematic unified analysis for the current advancements in deep reinforcement learning, and help to construct robust deep neural policies with improved generalization abilities.
Detecting Adversarial Directions in Deep Reinforcement Learning to Make Robust Decisions
Jun 09, 2023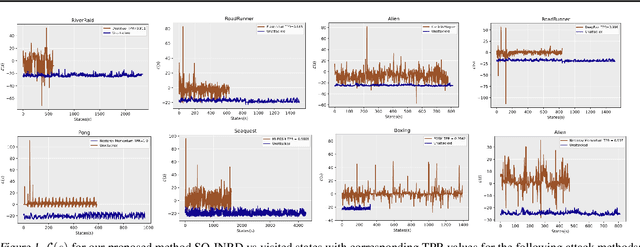
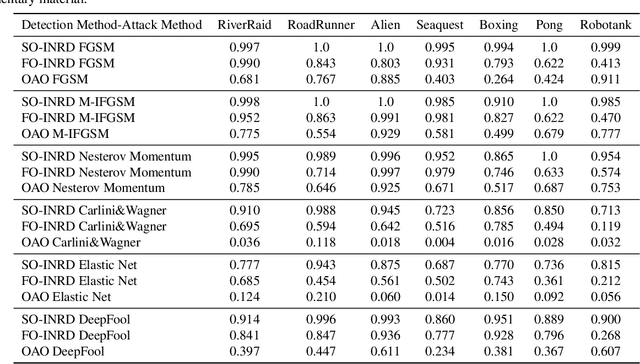
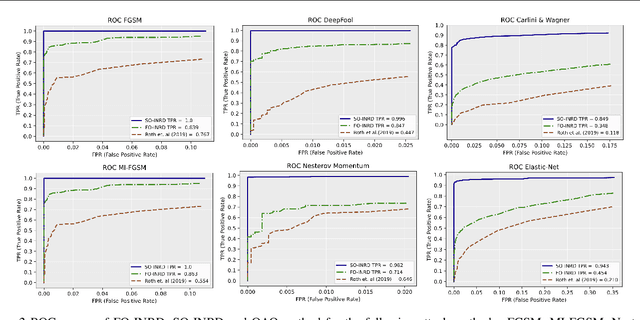

Learning in MDPs with highly complex state representations is currently possible due to multiple advancements in reinforcement learning algorithm design. However, this incline in complexity, and furthermore the increase in the dimensions of the observation came at the cost of volatility that can be taken advantage of via adversarial attacks (i.e. moving along worst-case directions in the observation space). To solve this policy instability problem we propose a novel method to detect the presence of these non-robust directions via local quadratic approximation of the deep neural policy loss. Our method provides a theoretical basis for the fundamental cut-off between safe observations and adversarial observations. Furthermore, our technique is computationally efficient, and does not depend on the methods used to produce the worst-case directions. We conduct extensive experiments in the Arcade Learning Environment with several different adversarial attack techniques. Most significantly, we demonstrate the effectiveness of our approach even in the setting where non-robust directions are explicitly optimized to circumvent our proposed method.
Adversarial Robust Deep Reinforcement Learning Requires Redefining Robustness
Jan 17, 2023



Learning from raw high dimensional data via interaction with a given environment has been effectively achieved through the utilization of deep neural networks. Yet the observed degradation in policy performance caused by imperceptible worst-case policy dependent translations along high sensitivity directions (i.e. adversarial perturbations) raises concerns on the robustness of deep reinforcement learning policies. In our paper, we show that these high sensitivity directions do not lie only along particular worst-case directions, but rather are more abundant in the deep neural policy landscape and can be found via more natural means in a black-box setting. Furthermore, we show that vanilla training techniques intriguingly result in learning more robust policies compared to the policies learnt via the state-of-the-art adversarial training techniques. We believe our work lays out intriguing properties of the deep reinforcement learning policy manifold and our results can help to build robust and generalizable deep reinforcement learning policies.
Deep Reinforcement Learning Policies Learn Shared Adversarial Features Across MDPs
Dec 16, 2021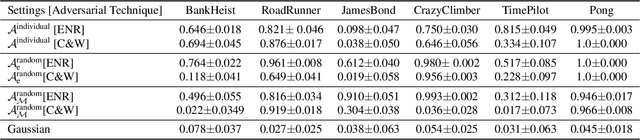
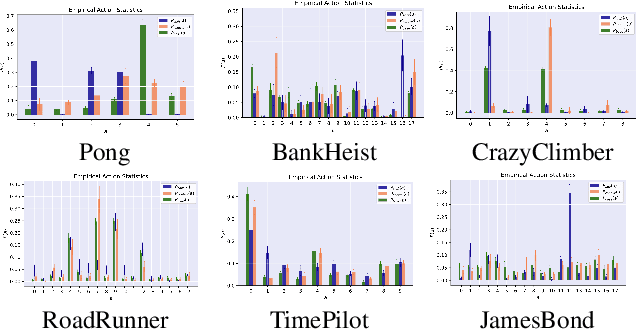
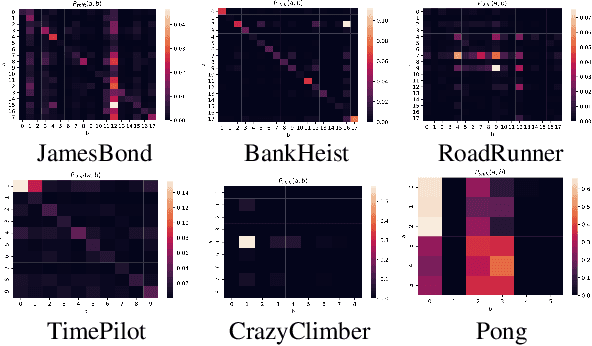
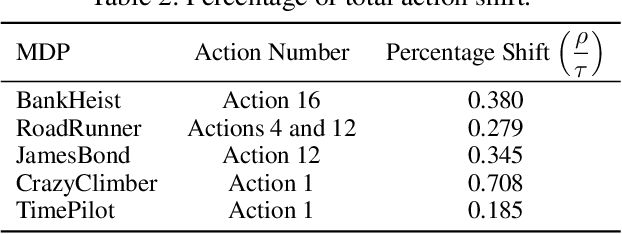
The use of deep neural networks as function approximators has led to striking progress for reinforcement learning algorithms and applications. Yet the knowledge we have on decision boundary geometry and the loss landscape of neural policies is still quite limited. In this paper we propose a framework to investigate the decision boundary and loss landscape similarities across states and across MDPs. We conduct experiments in various games from Arcade Learning Environment, and discover that high sensitivity directions for neural policies are correlated across MDPs. We argue that these high sensitivity directions support the hypothesis that non-robust features are shared across training environments of reinforcement learning agents. We believe our results reveal fundamental properties of the environments used in deep reinforcement learning training, and represent a tangible step towards building robust and reliable deep reinforcement learning agents.
Investigating Vulnerabilities of Deep Neural Policies
Aug 30, 2021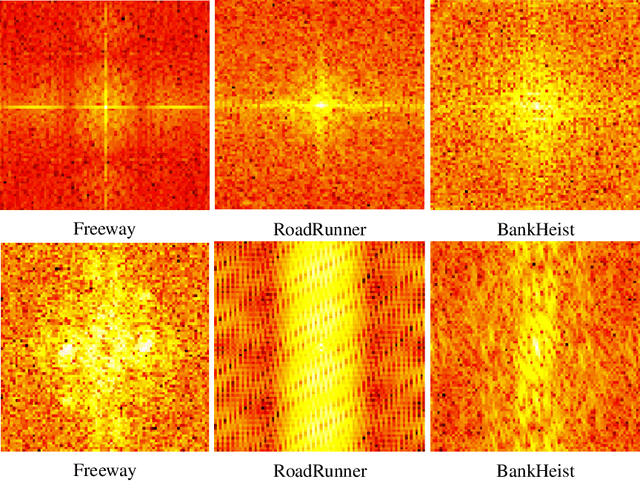

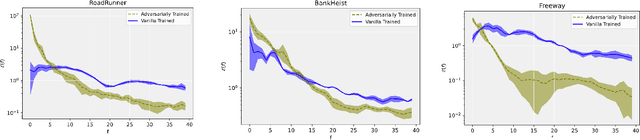
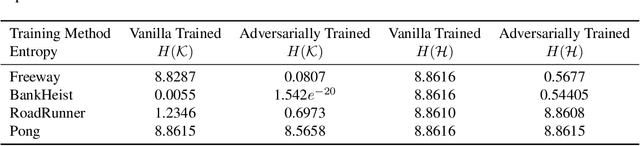
Reinforcement learning policies based on deep neural networks are vulnerable to imperceptible adversarial perturbations to their inputs, in much the same way as neural network image classifiers. Recent work has proposed several methods to improve the robustness of deep reinforcement learning agents to adversarial perturbations based on training in the presence of these imperceptible perturbations (i.e. adversarial training). In this paper, we study the effects of adversarial training on the neural policy learned by the agent. In particular, we follow two distinct parallel approaches to investigate the outcomes of adversarial training on deep neural policies based on worst-case distributional shift and feature sensitivity. For the first approach, we compare the Fourier spectrum of minimal perturbations computed for both adversarially trained and vanilla trained neural policies. Via experiments in the OpenAI Atari environments we show that minimal perturbations computed for adversarially trained policies are more focused on lower frequencies in the Fourier domain, indicating a higher sensitivity of these policies to low frequency perturbations. For the second approach, we propose a novel method to measure the feature sensitivities of deep neural policies and we compare these feature sensitivity differences in state-of-the-art adversarially trained deep neural policies and vanilla trained deep neural policies. We believe our results can be an initial step towards understanding the relationship between adversarial training and different notions of robustness for neural policies.