 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeural Network Exemplar Parallelization with Go
Sep 15, 2023



This paper presents a case for exemplar parallelism of neural networks using Go as parallelization framework. Further it is shown that also limited multi-core hardware systems are feasible for these parallelization tasks, as notebooks and single board computer systems. The main question was how much speedup can be generated when using concurrent Go goroutines specifically. A simple concurrent feedforward network for MNIST digit recognition with the programming language Go was created to find the answer. The first findings when using a notebook (Lenovo Yoga 2) showed a speedup of 252% when utilizing 4 goroutines. Testing a single board computer (Banana Pi M3) delivered more convincing results: 320% with 4 goroutines, and 432% with 8 goroutines.
Parallel Neural Networks in Golang
Apr 19, 2023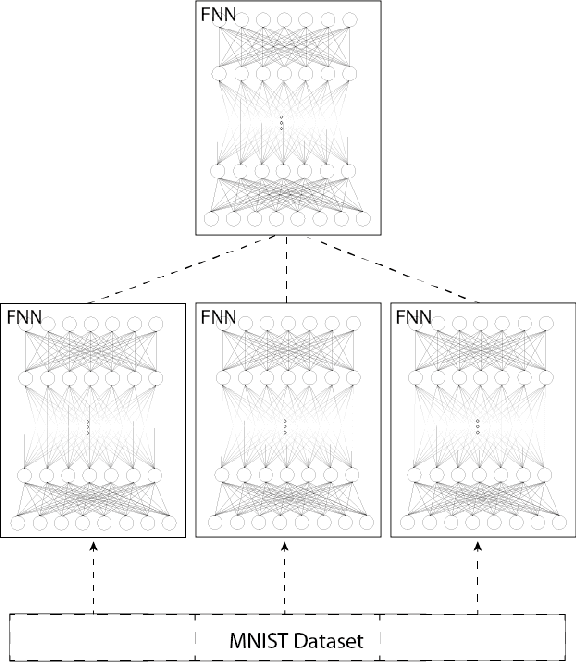



This paper describes the design and implementation of parallel neural networks (PNNs) with the novel programming language Golang. We follow in our approach the classical Single-Program Multiple-Data (SPMD) model where a PNN is composed of several sequential neural networks, which are trained with a proportional share of the training dataset. We used for this purpose the MNIST dataset, which contains binary images of handwritten digits. Our analysis focusses on different activation functions and optimizations in the form of stochastic gradients and initialization of weights and biases. We conduct a thorough performance analysis, where network configurations and different performance factors are analyzed and interpreted. Golang and its inherent parallelization support proved very well for parallel neural network simulation by considerable decreased processing times compared to sequential variants.
Error-guided likelihood-free MCMC
Oct 13, 2020
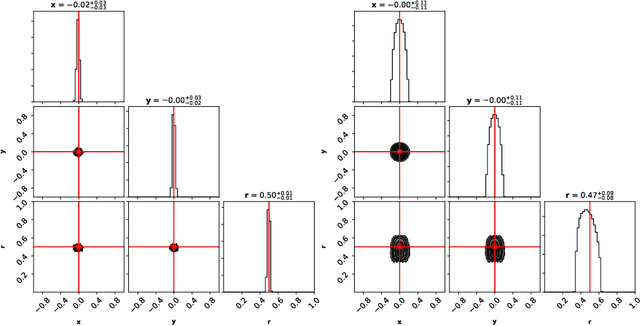
This work presents a novel posterior inference method for models with intractable evidence and likelihood functions. Error-guided likelihood-free MCMC, or EG-LF-MCMC in short, has been developed for scientific applications, where a researcher is interested in obtaining approximate posterior densities over model parameters, while avoiding the need for expensive training of component estimators on full observational data or the tedious design of expressive summary statistics, as in related approaches. Our technique is based on two phases. In the first phase, we draw samples from the prior, simulate respective observations and record their errors $\epsilon$ in relation to the true observation. We train a classifier to distinguish between corresponding and non-corresponding $(\epsilon, \boldsymbol{\theta})$-tuples. In the second stage the said classifier is conditioned on the smallest recorded $\epsilon$ value from the training set and employed for the calculation of transition probabilities in a Markov Chain Monte Carlo sampling procedure. By conditioning the MCMC on specific $\epsilon$ values, our method may also be used in an amortized fashion to infer posterior densities for observations, which are located a given distance away from the observed data. We evaluate the proposed method on benchmark problems with semantically and structurally different data and compare its performance against the state of the art approximate Bayesian computation (ABC).
N2Sky - Neural Networks as Services in the Clouds
Jan 10, 2014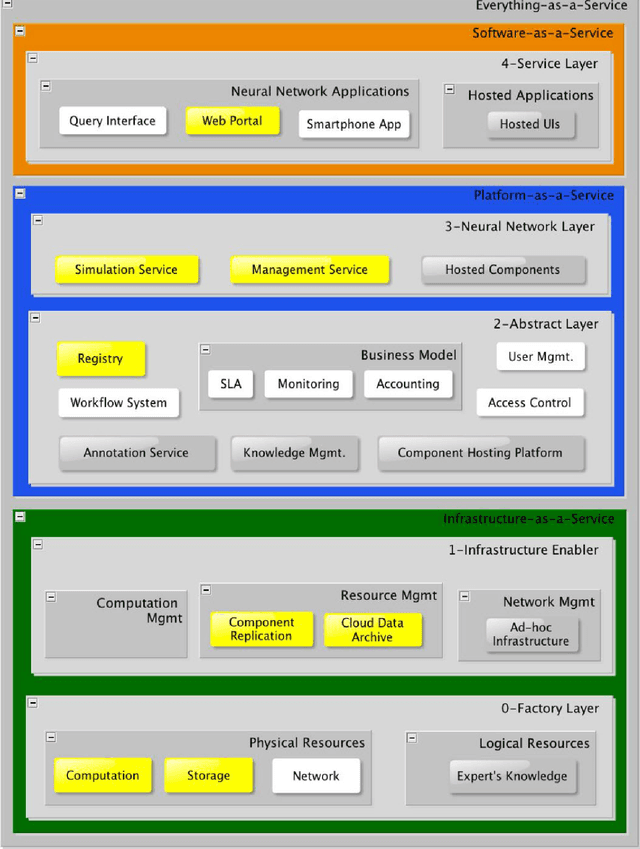
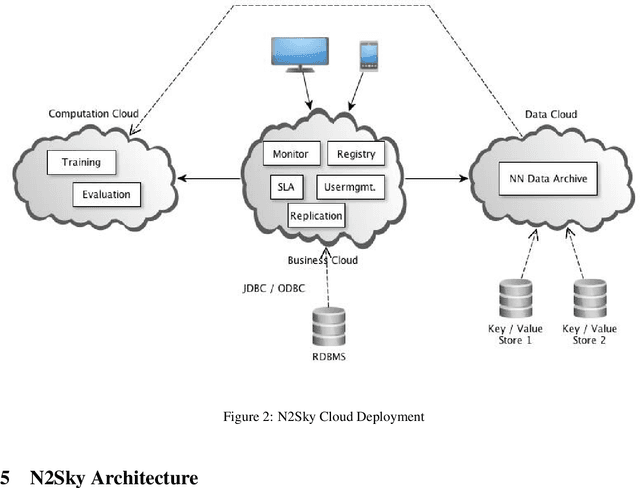
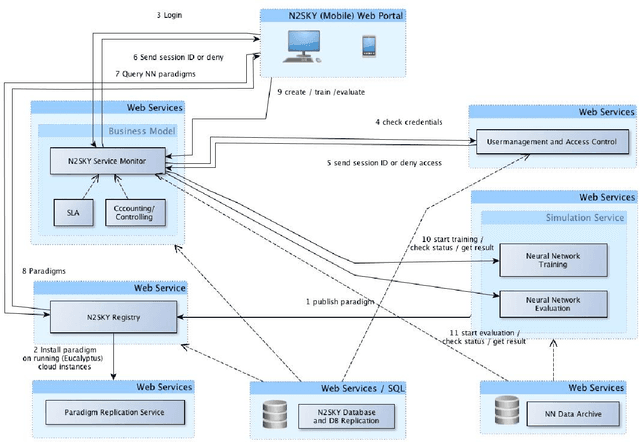
We present the N2Sky system, which provides a framework for the exchange of neural network specific knowledge, as neural network paradigms and objects, by a virtual organization environment. It follows the sky computing paradigm delivering ample resources by the usage of federated Clouds. N2Sky is a novel Cloud-based neural network simulation environment, which follows a pure service oriented approach. The system implements a transparent environment aiming to enable both novice and experienced users to do neural network research easily and comfortably. N2Sky is built using the RAVO reference architecture of virtual organizations which allows itself naturally integrating into the Cloud service stack (SaaS, PaaS, and IaaS) of service oriented architectures.
Neural Networks and Database Systems
Feb 25, 2008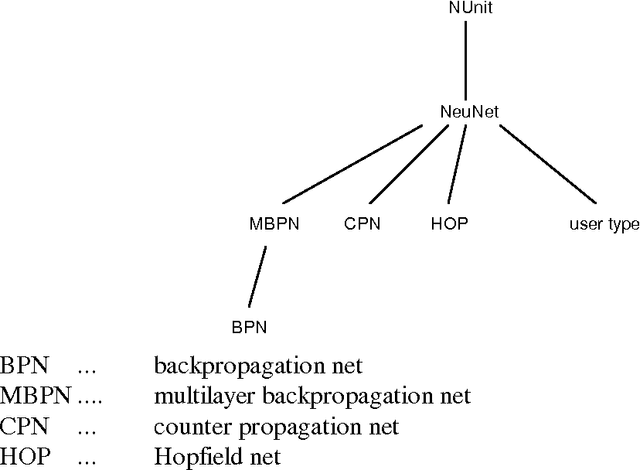
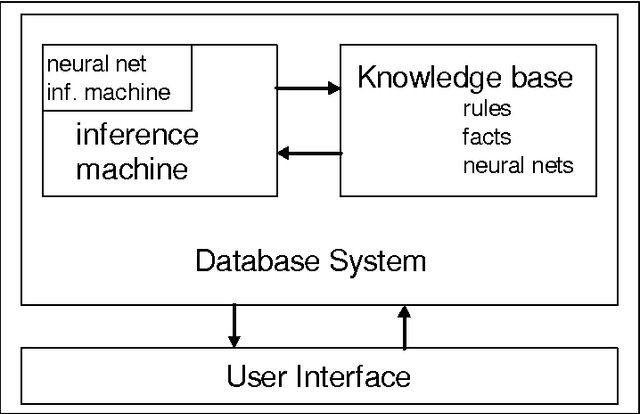
Object-oriented database systems proved very valuable at handling and administrating complex objects. In the following guidelines for embedding neural networks into such systems are presented. It is our goal to treat networks as normal data in the database system. From the logical point of view, a neural network is a complex data value and can be stored as a normal data object. It is generally accepted that rule-based reasoning will play an important role in future database applications. The knowledge base consists of facts and rules, which are both stored and handled by the underlying database system. Neural networks can be seen as representation of intensional knowledge of intelligent database systems. So they are part of a rule based knowledge pool and can be used like conventional rules. The user has a unified view about his knowledge base regardless of the origin of the unique rules.
* 19 pages, Festschrift Informationssysteme, in honor of G. Vinek