 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDe-jargonizing Science for Journalists with GPT-4: A Pilot Study
Oct 15, 2024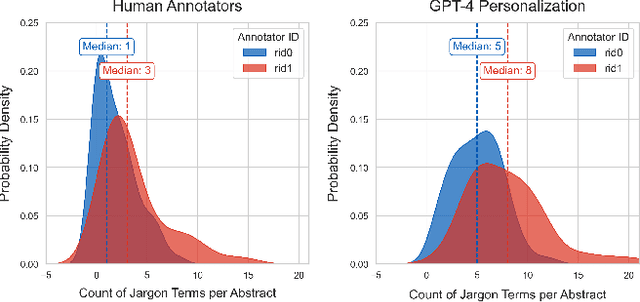
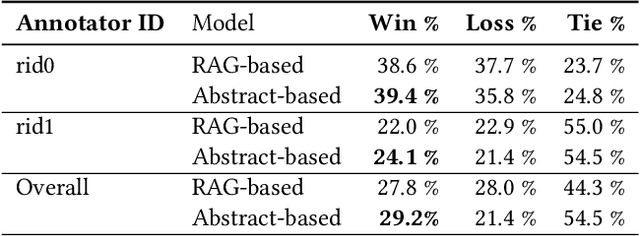

This study offers an initial evaluation of a human-in-the-loop system leveraging GPT-4 (a large language model or LLM), and Retrieval-Augmented Generation (RAG) to identify and define jargon terms in scientific abstracts, based on readers' self-reported knowledge. The system achieves fairly high recall in identifying jargon and preserves relative differences in readers' jargon identification, suggesting personalization as a feasible use-case for LLMs to support sense-making of complex information. Surprisingly, using only abstracts for context to generate definitions yields slightly more accurate and higher quality definitions than using RAG-based context from the fulltext of an article. The findings highlight the potential of generative AI for assisting science reporters, and can inform future work on developing tools to simplify dense documents.