 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating quantum generative models via imbalanced data classification benchmarks
Aug 21, 2023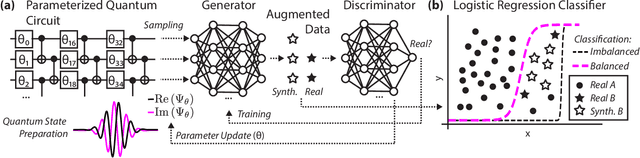
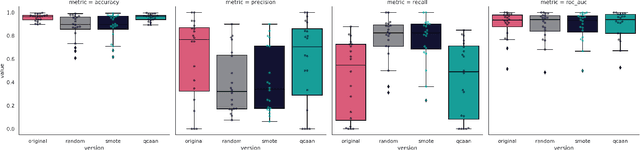
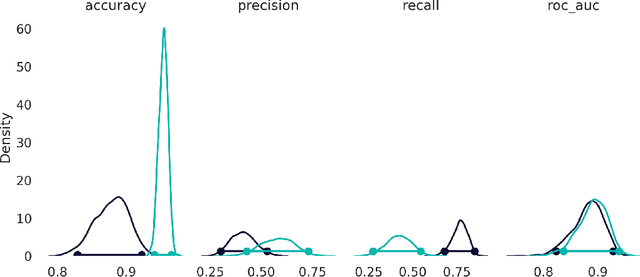
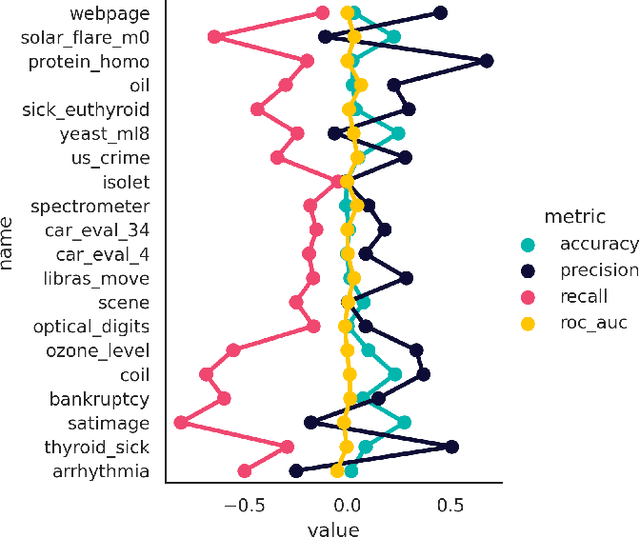
A limited set of tools exist for assessing whether the behavior of quantum machine learning models diverges from conventional models, outside of abstract or theoretical settings. We present a systematic application of explainable artificial intelligence techniques to analyze synthetic data generated from a hybrid quantum-classical neural network adapted from twenty different real-world data sets, including solar flares, cardiac arrhythmia, and speech data. Each of these data sets exhibits varying degrees of complexity and class imbalance. We benchmark the quantum-generated data relative to state-of-the-art methods for mitigating class imbalance for associated classification tasks. We leverage this approach to elucidate the qualities of a problem that make it more or less likely to be amenable to a hybrid quantum-classical generative model.
Exploring BERT Parameter Efficiency on the Stanford Question Answering Dataset v2.0
Mar 03, 2020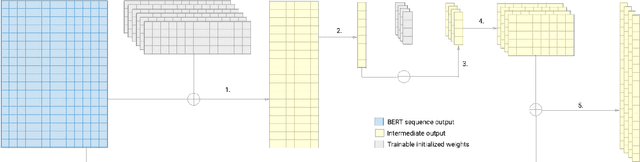
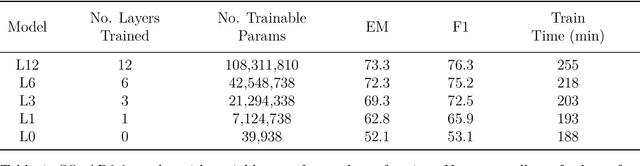
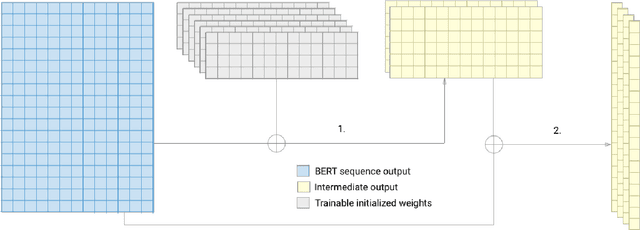

In this paper we explore the parameter efficiency of BERT arXiv:1810.04805 on version 2.0 of the Stanford Question Answering dataset (SQuAD2.0). We evaluate the parameter efficiency of BERT while freezing a varying number of final transformer layers as well as including the adapter layers proposed in arXiv:1902.00751. Additionally, we experiment with the use of context-aware convolutional (CACNN) filters, as described in arXiv:1709.08294v3, as a final augmentation layer for the SQuAD2.0 tasks. This exploration is motivated in part by arXiv:1907.10597, which made a compelling case for broadening the evaluation criteria of artificial intelligence models to include various measures of resource efficiency. While we do not evaluate these models based on their floating point operation efficiency as proposed in arXiv:1907.10597, we examine efficiency with respect to training time, inference time, and total number of model parameters. Our results largely corroborate those of arXiv:1902.00751 for adapter modules, while also demonstrating that gains in F1 score from adding context-aware convolutional filters are not practical due to the increase in training and inference time.
Exploring Neural Net Augmentation to BERT for Question Answering on SQUAD 2.0
Aug 04, 2019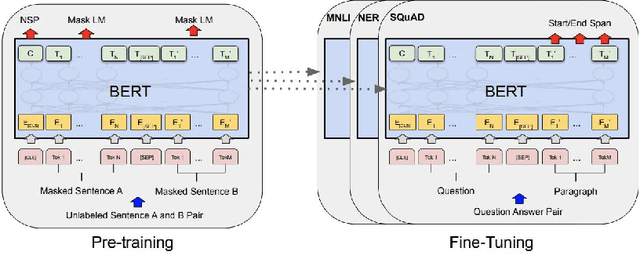
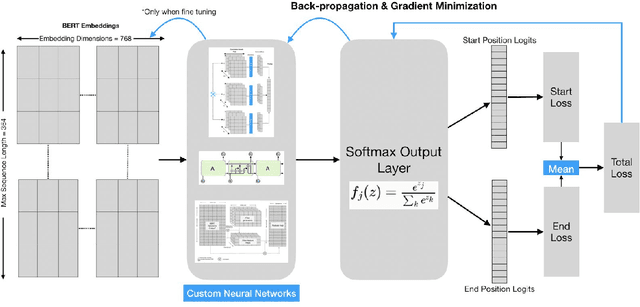
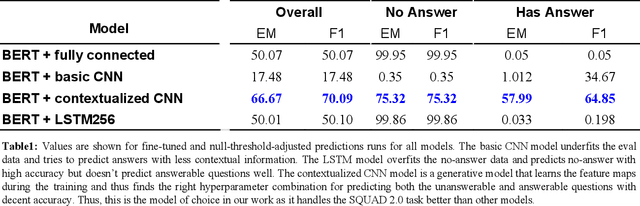
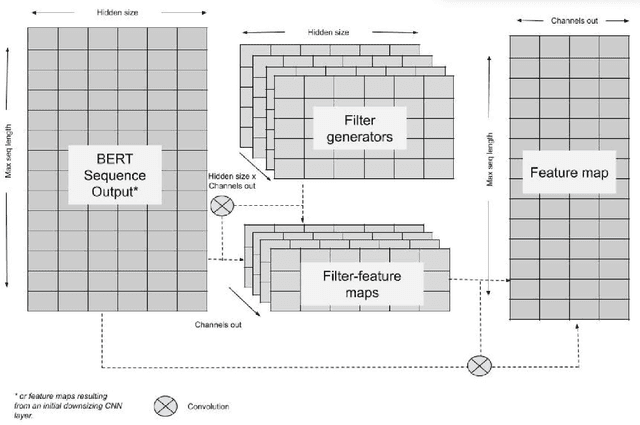
Enhancing machine capabilities to answer questions has been a topic of considerable focus in recent years of NLP research. Language models like Embeddings from Language Models (ELMo)[1] and Bidirectional Encoder Representations from Transformers (BERT) [2] have been very successful in developing general purpose language models that can be optimized for a large number of downstream language tasks. In this work, we focused on augmenting the pre-trained BERT language model with different output neural net architectures and compared their performance on question answering task posed by the Stanford Question Answering Dataset 2.0 (SQUAD 2.0) [3]. Additionally, we also fine-tuned the pre-trained BERT model parameters to demonstrate its effectiveness in adapting to specialized language tasks. Our best output network, is the contextualized CNN that performs on both the unanswerable and answerable question answering tasks with F1 scores of 75.32 and 64.85 respectively.