 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLEA: Improving Sentence Similarity Robustness to Typos Using Lexical Attention Bias
Jul 06, 2023

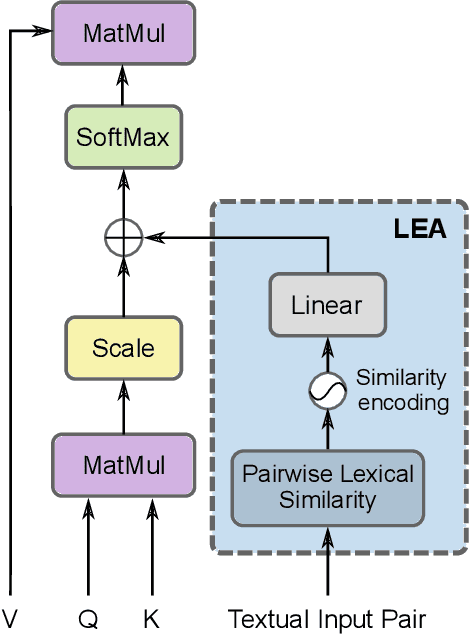

Textual noise, such as typos or abbreviations, is a well-known issue that penalizes vanilla Transformers for most downstream tasks. We show that this is also the case for sentence similarity, a fundamental task in multiple domains, e.g. matching, retrieval or paraphrasing. Sentence similarity can be approached using cross-encoders, where the two sentences are concatenated in the input allowing the model to exploit the inter-relations between them. Previous works addressing the noise issue mainly rely on data augmentation strategies, showing improved robustness when dealing with corrupted samples that are similar to the ones used for training. However, all these methods still suffer from the token distribution shift induced by typos. In this work, we propose to tackle textual noise by equipping cross-encoders with a novel LExical-aware Attention module (LEA) that incorporates lexical similarities between words in both sentences. By using raw text similarities, our approach avoids the tokenization shift problem obtaining improved robustness. We demonstrate that the attention bias introduced by LEA helps cross-encoders to tackle complex scenarios with textual noise, specially in domains with short-text descriptions and limited context. Experiments using three popular Transformer encoders in five e-commerce datasets for product matching show that LEA consistently boosts performance under the presence of noise, while remaining competitive on the original (clean) splits. We also evaluate our approach in two datasets for textual entailment and paraphrasing showing that LEA is robust to typos in domains with longer sentences and more natural context. Additionally, we thoroughly analyze several design choices in our approach, providing insights about the impact of the decisions made and fostering future research in cross-encoders dealing with typos.
Block-SCL: Blocking Matters for Supervised Contrastive Learning in Product Matching
Jul 05, 2022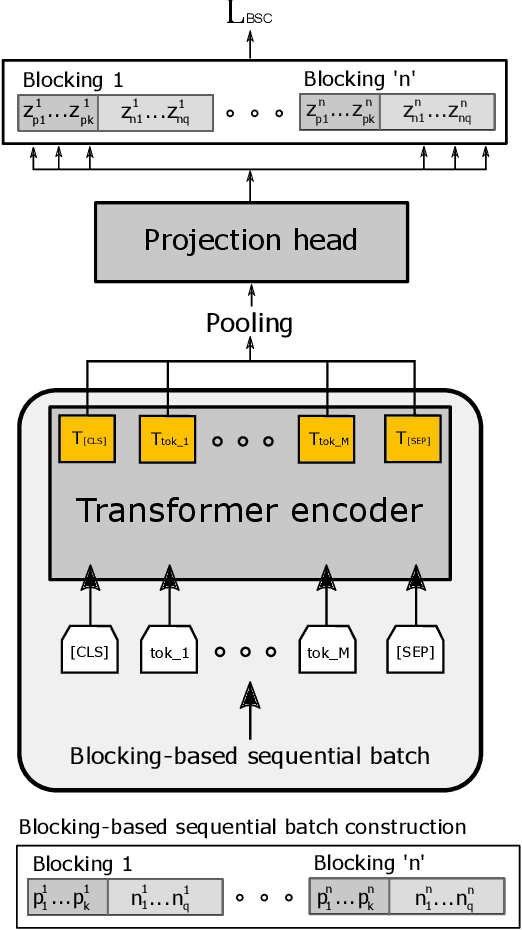
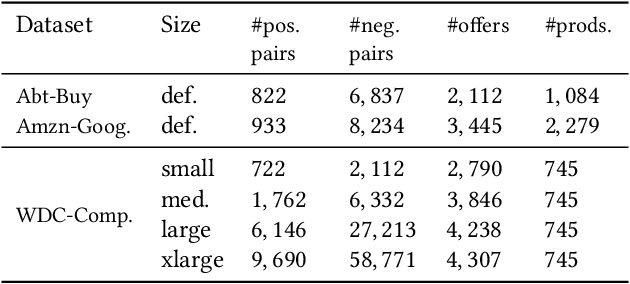
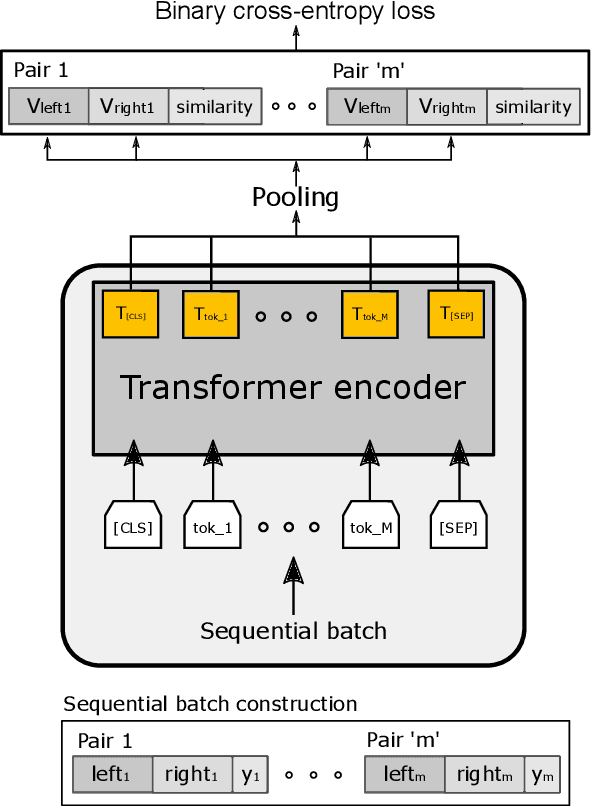
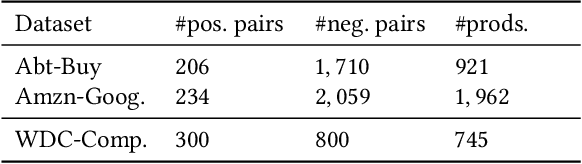
Product matching is a fundamental step for the global understanding of consumer behavior in e-commerce. In practice, product matching refers to the task of deciding if two product offers from different data sources (e.g. retailers) represent the same product. Standard pipelines use a previous stage called blocking, where for a given product offer a set of potential matching candidates are retrieved based on similar characteristics (e.g. same brand, category, flavor, etc.). From these similar product candidates, those that are not a match can be considered hard negatives. We present Block-SCL, a strategy that uses the blocking output to make the most of Supervised Contrastive Learning (SCL). Concretely, Block-SCL builds enriched batches using the hard-negatives samples obtained in the blocking stage. These batches provide a strong training signal leading the model to learn more meaningful sentence embeddings for product matching. Experimental results in several public datasets demonstrate that Block-SCL achieves state-of-the-art results despite only using short product titles as input, no data augmentation, and a lighter transformer backbone than competing methods.