 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multimodal Bayesian Network for symptom-level depression and anxiety prediction from voice and speech data
Dec 08, 2025During psychiatric assessment, clinicians observe not only what patients report, but important nonverbal signs such as tone, speech rate, fluency, responsiveness, and body language. Weighing and integrating these different information sources is a challenging task and a good candidate for support by intelligence-driven tools - however this is yet to be realized in the clinic. Here, we argue that several important barriers to adoption can be addressed using Bayesian network modelling. To demonstrate this, we evaluate a model for depression and anxiety symptom prediction from voice and speech features in large-scale datasets (30,135 unique speakers). Alongside performance for conditions and symptoms (for depression, anxiety ROC-AUC=0.842,0.831 ECE=0.018,0.015; core individual symptom ROC-AUC>0.74), we assess demographic fairness and investigate integration across and redundancy between different input modality types. Clinical usefulness metrics and acceptability to mental health service users are explored. When provided with sufficiently rich and large-scale multimodal data streams and specified to represent common mental conditions at the symptom rather than disorder level, such models are a principled approach for building robust assessment support tools: providing clinically-relevant outputs in a transparent and explainable format that is directly amenable to expert clinical supervision.
Path Signature Representation of Patient-Clinician Interactions as a Predictor for Neuropsychological Tests Outcomes in Children: A Proof of Concept
Dec 12, 2023This research report presents a proof-of-concept study on the application of machine learning techniques to video and speech data collected during diagnostic cognitive assessments of children with a neurodevelopmental disorder. The study utilised a dataset of 39 video recordings, capturing extensive sessions where clinicians administered, among other things, four cognitive assessment tests. From the first 40 minutes of each clinical session, covering the administration of the Wechsler Intelligence Scale for Children (WISC-V), we extracted head positions and speech turns of both clinician and child. Despite the limited sample size and heterogeneous recording styles, the analysis successfully extracted path signatures as features from the recorded data, focusing on patient-clinician interactions. Importantly, these features quantify the interpersonal dynamics of the assessment process (dialogue and movement patterns). Results suggest that these features exhibit promising potential for predicting all cognitive tests scores of the entire session length and for prototyping a predictive model as a clinical decision support tool. Overall, this proof of concept demonstrates the feasibility of leveraging machine learning techniques for clinical video and speech data analysis in order to potentially enhance the efficiency of cognitive assessments for neurodevelopmental disorders in children.
Utilising Bayesian Networks to combine multimodal data and expert opinion for the robust prediction of depression and its symptoms
Nov 09, 2022



Predicting the presence of major depressive disorder (MDD) using behavioural and cognitive signals is a highly non-trivial task. The heterogeneous clinical profile of MDD means that any given speech, facial expression and/or observed cognitive pattern may be associated with a unique combination of depressive symptoms. Conventional discriminative machine learning models potentially lack the complexity to robustly model this heterogeneity. Bayesian networks, however, may instead be well-suited to such a scenario. These networks are probabilistic graphical models that efficiently describe the joint probability distribution over a set of random variables by explicitly capturing their conditional dependencies. This framework provides further advantages over standard discriminative modelling by offering the possibility to incorporate expert opinion in the graphical structure of the models, generating explainable model predictions, informing about the uncertainty of predictions, and naturally handling missing data. In this study, we apply a Bayesian framework to capture the relationships between depression, depression symptoms, and features derived from speech, facial expression and cognitive game data collected at thymia.
Speech and the n-Back task as a lens into depression. How combining both may allow us to isolate different core symptoms of depression
Mar 30, 2022

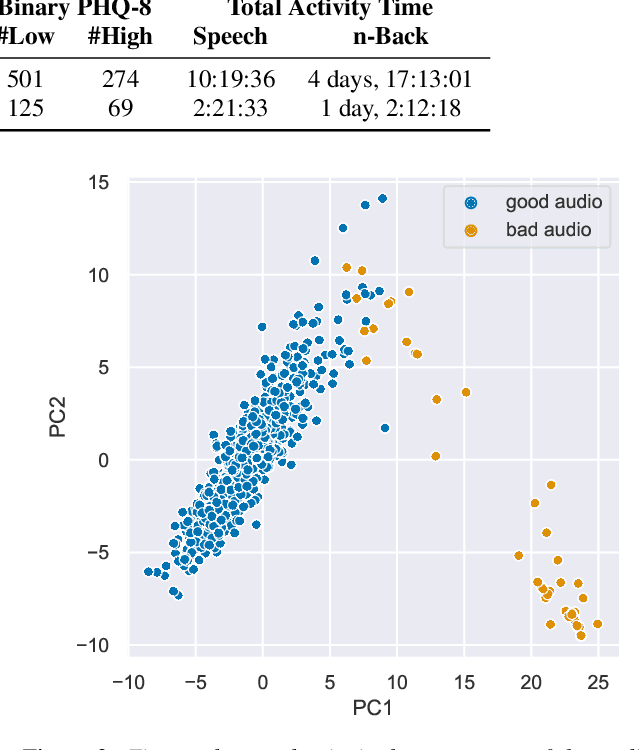
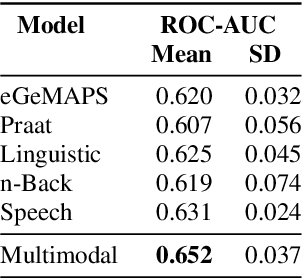
Embedded in any speech signal is a rich combination of cognitive, neuromuscular and physiological information. This richness makes speech a powerful signal in relation to a range of different health conditions, including major depressive disorders (MDD). One pivotal issue in speech-depression research is the assumption that depressive severity is the dominant measurable effect. However, given the heterogeneous clinical profile of MDD, it may actually be the case that speech alterations are more strongly associated with subsets of key depression symptoms. This paper presents strong evidence in support of this argument. First, we present a novel large, cross-sectional, multi-modal dataset collected at Thymia. We then present a set of machine learning experiments that demonstrate that combining speech with features from an n-Back working memory assessment improves classifier performance when predicting the popular eight-item Patient Health Questionnaire depression scale (PHQ-8). Finally, we present a set of experiments that highlight the association between different speech and n-Back markers at the PHQ-8 item level. Specifically, we observe that somatic and psychomotor symptoms are more strongly associated with n-Back performance scores, whilst the other items: anhedonia, depressed mood, change in appetite, feelings of worthlessness and trouble concentrating are more strongly associated with speech changes.