 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePreserving Product Fidelity in Large Scale Image Recontextualization with Diffusion Models
Mar 11, 2025
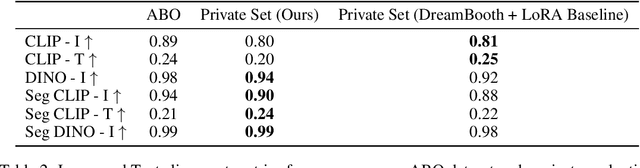


We present a framework for high-fidelity product image recontextualization using text-to-image diffusion models and a novel data augmentation pipeline. This pipeline leverages image-to-video diffusion, in/outpainting & negatives to create synthetic training data, addressing limitations of real-world data collection for this task. Our method improves the quality and diversity of generated images by disentangling product representations and enhancing the model's understanding of product characteristics. Evaluation on the ABO dataset and a private product dataset, using automated metrics and human assessment, demonstrates the effectiveness of our framework in generating realistic and compelling product visualizations, with implications for applications such as e-commerce and virtual product showcasing.