 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable Detection of Salient Entities in News Articles
May 30, 2024

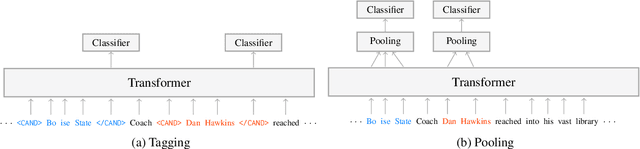

News articles typically mention numerous entities, a large fraction of which are tangential to the story. Detecting the salience of entities in articles is thus important to applications such as news search, analysis and summarization. In this work, we explore new approaches for efficient and effective salient entity detection by fine-tuning pretrained transformer models with classification heads that use entity tags or contextualized entity representations directly. Experiments show that these straightforward techniques dramatically outperform prior work across datasets with varying sizes and salience definitions. We also study knowledge distillation techniques to effectively reduce the computational cost of these models without affecting their accuracy. Finally, we conduct extensive analyses and ablation experiments to characterize the behavior of the proposed models.