 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta4XNLI: A Crosslingual Parallel Corpus for Metaphor Detection and Interpretation
Apr 10, 2024Metaphors, although occasionally unperceived, are ubiquitous in our everyday language. Thus, it is crucial for Language Models to be able to grasp the underlying meaning of this kind of figurative language. In this work, we present Meta4XNLI, a novel parallel dataset for the tasks of metaphor detection and interpretation that contains metaphor annotations in both Spanish and English. We investigate language models' metaphor identification and understanding abilities through a series of monolingual and cross-lingual experiments by leveraging our proposed corpus. In order to comprehend how these non-literal expressions affect models' performance, we look over the results and perform an error analysis. Additionally, parallel data offers many potential opportunities to investigate metaphor transferability between these languages and the impact of translation on the development of multilingual annotated resources.
Leveraging a New Spanish Corpus for Multilingual and Crosslingual Metaphor Detection
Oct 19, 2022

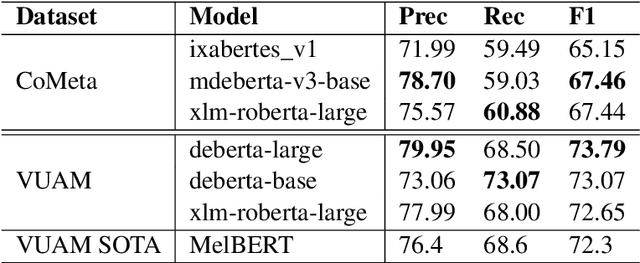

The lack of wide coverage datasets annotated with everyday metaphorical expressions for languages other than English is striking. This means that most research on supervised metaphor detection has been published only for that language. In order to address this issue, this work presents the first corpus annotated with naturally occurring metaphors in Spanish large enough to develop systems to perform metaphor detection. The presented dataset, CoMeta, includes texts from various domains, namely, news, political discourse, Wikipedia and reviews. In order to label CoMeta, we apply the MIPVU method, the guidelines most commonly used to systematically annotate metaphor on real data. We use our newly created dataset to provide competitive baselines by fine-tuning several multilingual and monolingual state-of-the-art large language models. Furthermore, by leveraging the existing VUAM English data in addition to CoMeta, we present the, to the best of our knowledge, first cross-lingual experiments on supervised metaphor detection. Finally, we perform a detailed error analysis that explores the seemingly high transfer of everyday metaphor across these two languages and datasets.