 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSSDBCODI: Semi-Supervised Density-Based Clustering with Outliers Detection Integrated
Aug 10, 2022
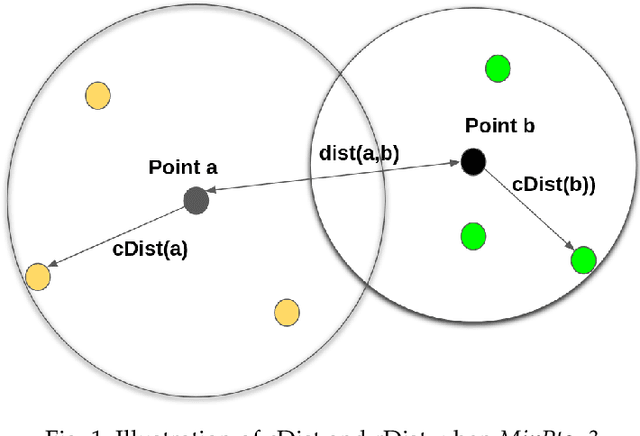
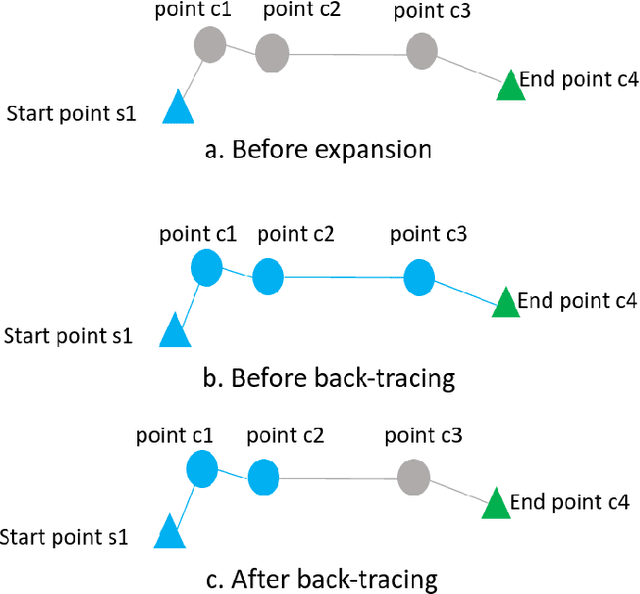
Clustering analysis is one of the critical tasks in machine learning. Traditionally, clustering has been an independent task, separate from outlier detection. Due to the fact that the performance of clustering can be significantly eroded by outliers, a small number of algorithms try to incorporate outlier detection in the process of clustering. However, most of those algorithms are based on unsupervised partition-based algorithms such as k-means. Given the nature of those algorithms, they often fail to deal with clusters of complex, non-convex shapes. To tackle this challenge, we have proposed SSDBCODI, a semi-supervised density-based algorithm. SSDBCODI combines the advantage of density-based algorithms, which are capable of dealing with clusters of complex shapes, with the semi-supervised element, which offers flexibility to adjust the clustering results based on a few user labels. We also merge an outlier detection component with the clustering process. Potential outliers are detected based on three scores generated during the process: (1) reachability-score, which measures how density-reachable a point is to a labeled normal object, (2) local-density-score, which measures the neighboring density of data objects, and (3) similarity-score, which measures the closeness of a point to its nearest labeled outliers. Then in the following step, instance weights are generated for each data instance based on those three scores before being used to train a classifier for further clustering and outlier detection. To enhance the understanding of the proposed algorithm, for our evaluation, we have run our proposed algorithm against some of the state-of-art approaches on multiple datasets and separately listed the results of outlier detection apart from clustering. Our results indicate that our algorithm can achieve superior results with a small percentage of labels.
Synthetic Sampling for Multi-Class Malignancy Prediction
Jul 07, 2018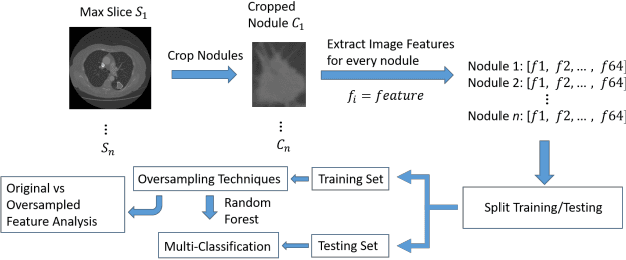

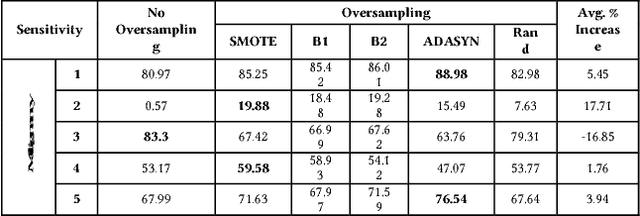
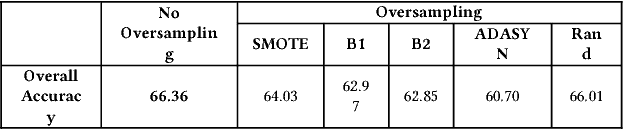
We explore several oversampling techniques for an imbalanced multi-label classification problem, a setting often encountered when developing models for Computer-Aided Diagnosis (CADx) systems. While most CADx systems aim to optimize classifiers for overall accuracy without considering the relative distribution of each class, we look into using synthetic sampling to increase per-class performance when predicting the degree of malignancy. Using low-level image features and a random forest classifier, we show that using synthetic oversampling techniques increases the sensitivity of the minority classes by an average of 7.22% points, with as much as a 19.88% point increase in sensitivity for a particular minority class. Furthermore, the analysis of low-level image feature distributions for the synthetic nodules reveals that these nodules can provide insights on how to preprocess image data for better classification performance or how to supplement the original datasets when more data acquisition is feasible.