 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General-Purpose Diversified 2D Seismic Image Dataset from NAMSS
Jan 27, 2026We introduce the Unicamp-NAMSS dataset, a large, diverse, and geographically distributed collection of migrated 2D seismic sections designed to support modern machine learning research in geophysics. We constructed the dataset from the National Archive of Marine Seismic Surveys (NAMSS), which contains decades of publicly available marine seismic data acquired across multiple regions, acquisition conditions, and geological settings. After a comprehensive collection and filtering process, we obtained 2588 cleaned and standardized seismic sections from 122 survey areas, covering a wide range of vertical and horizontal sampling characteristics. To ensure reliable experimentation, we balanced the dataset so that no survey dominates the distribution, and partitioned it into non-overlapping macro-regions for training, validation, and testing. This region-disjoint split allows robust evaluation of generalization to unseen geological and acquisition conditions. We validated the dataset through quantitative and embedding-space analyses using both convolutional and transformer-based models. These analyses showed that Unicamp-NAMSS exhibits substantial variability within and across regions, while maintaining coherent structure across acquisition macro-region and survey types. Comparisons with widely used interpretation datasets (Parihaka and F3 Block) further demonstrated that Unicamp-NAMSS covers a broader portion of the seismic appearance space, making it a strong candidate for machine learning model pretraining. The dataset, therefore, provides a valuable resource for machine learning tasks, including self-supervised representation learning, transfer learning, benchmarking supervised tasks such as super-resolution or attribute prediction, and studying domain adaptation in seismic interpretation.
Homomorphic WiSARDs: Efficient Weightless Neural Network training over encrypted data
Mar 29, 2024



The widespread application of machine learning algorithms is a matter of increasing concern for the data privacy research community, and many have sought to develop privacy-preserving techniques for it. Among existing approaches, the homomorphic evaluation of ML algorithms stands out by performing operations directly over encrypted data, enabling strong guarantees of confidentiality. The homomorphic evaluation of inference algorithms is practical even for relatively deep Convolution Neural Networks (CNNs). However, training is still a major challenge, with current solutions often resorting to lightweight algorithms that can be unfit for solving more complex problems, such as image recognition. This work introduces the homomorphic evaluation of Wilkie, Stonham, and Aleksander's Recognition Device (WiSARD) and subsequent Weightless Neural Networks (WNNs) for training and inference on encrypted data. Compared to CNNs, WNNs offer better performance with a relatively small accuracy drop. We develop a complete framework for it, including several building blocks that can be of independent interest. Our framework achieves 91.7% accuracy on the MNIST dataset after only 3.5 minutes of encrypted training (multi-threaded), going up to 93.8% in 3.5 hours. For the HAM10000 dataset, we achieve 67.9% accuracy in just 1.5 minutes, going up to 69.9% after 1 hour. Compared to the state of the art on the HE evaluation of CNN training, Glyph (Lou et al., NeurIPS 2020), these results represent a speedup of up to 1200 times with an accuracy loss of at most 5.4%. For HAM10000, we even achieved a 0.65% accuracy improvement while being 60 times faster than Glyph. We also provide solutions for small-scale encrypted training. In a single thread on a desktop machine using less than 200MB of memory, we train over 1000 MNIST images in 12 minutes or over the entire Wisconsin Breast Cancer dataset in just 11 seconds.
Efficiency and Scalability of Multi-Lane Capsule Networks (MLCN)
Aug 11, 2019



Some Deep Neural Networks (DNN) have what we call lanes, or they can be reorganized as such. Lanes are paths in the network which are data-independent and typically learn different features or add resilience to the network. Given their data-independence, lanes are amenable for parallel processing. The Multi-lane CapsNet (MLCN) is a proposed reorganization of the Capsule Network which is shown to achieve better accuracy while bringing highly-parallel lanes. However, the efficiency and scalability of MLCN had not been systematically examined. In this work, we study the MLCN network with multiple GPUs finding that it is 2x more efficient than the original CapsNet when using model-parallelism. Further, we present the load balancing problem of distributing heterogeneous lanes in homogeneous or heterogeneous accelerators and show that a simple greedy heuristic can be almost 50% faster than a naive random approach.
The Multi-Lane Capsule Network (MLCN)
Feb 22, 2019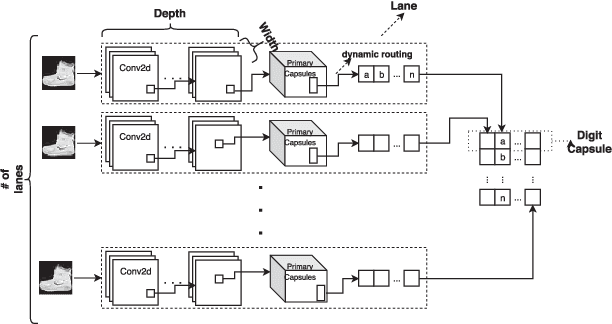


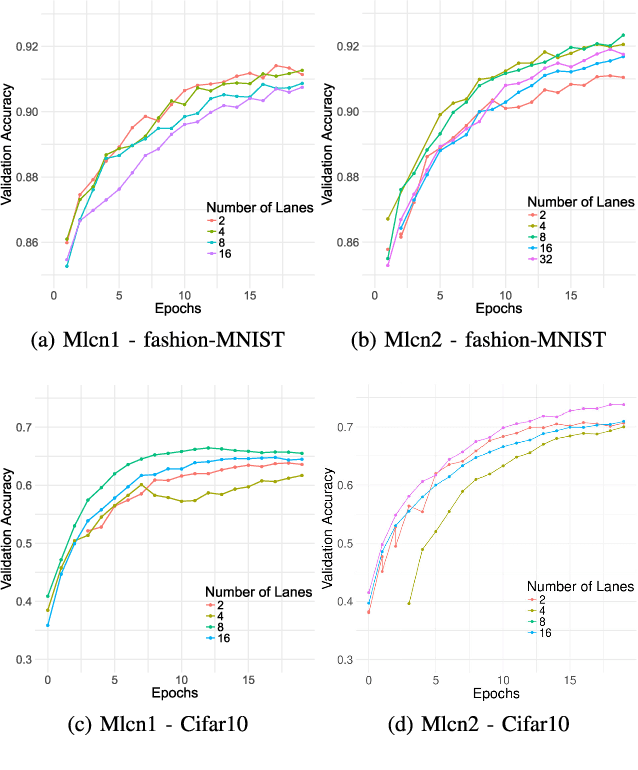
We introduce Multi-Lane Capsule Networks (MLCN), which are a separable and resource efficient organization of Capsule Networks (CapsNet) that allows parallel processing, while achieving high accuracy at reduced cost. A MLCN is composed of a number of (distinct) parallel lanes, each contributing to a dimension of the result, trained using the routing-by-agreement organization of CapsNet. Our results indicate similar accuracy with a much reduced cost in number of parameters for the Fashion-MNIST and Cifar10 datsets. They also indicate that the MLCN outperforms the original CapsNet when using a proposed novel configuration for the lanes. MLCN also has faster training and inference times, being more than two-fold faster than the original CapsNet in the same accelerator.