 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of user models based on GMM-UBM and i-vectors for speech, handwriting, and gait assessment of Parkinson's disease patients
Feb 13, 2020
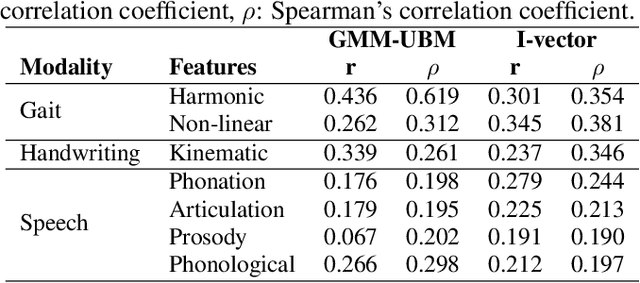
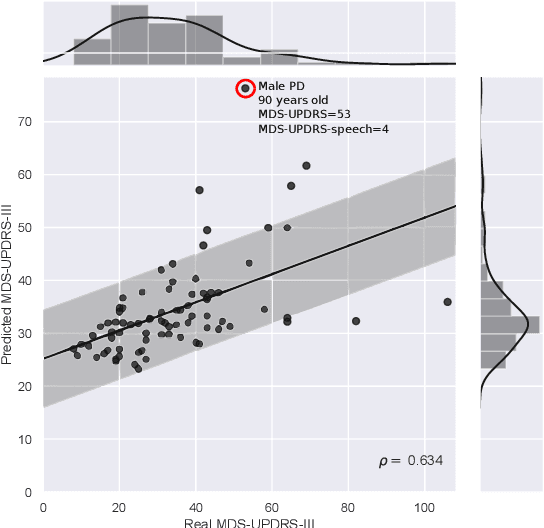
Parkinson's disease is a neurodegenerative disorder characterized by the presence of different motor impairments. Information from speech, handwriting, and gait signals have been considered to evaluate the neurological state of the patients. On the other hand, user models based on Gaussian mixture models - universal background models (GMM-UBM) and i-vectors are considered the state-of-the-art in biometric applications like speaker verification because they are able to model specific speaker traits. This study introduces the use of GMM-UBM and i-vectors to evaluate the neurological state of Parkinson's patients using information from speech, handwriting, and gait. The results show the importance of different feature sets from each type of signal in the assessment of the neurological state of the patients.
Analysis and Evaluation of Handwriting in Patients with Parkinson's Disease Using kinematic, Geometrical, and Non-linear Features
Feb 13, 2020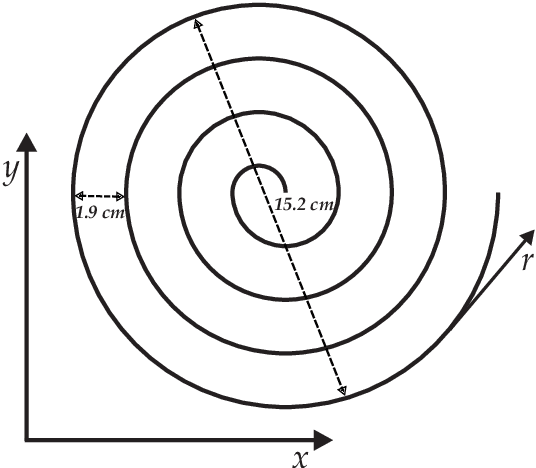
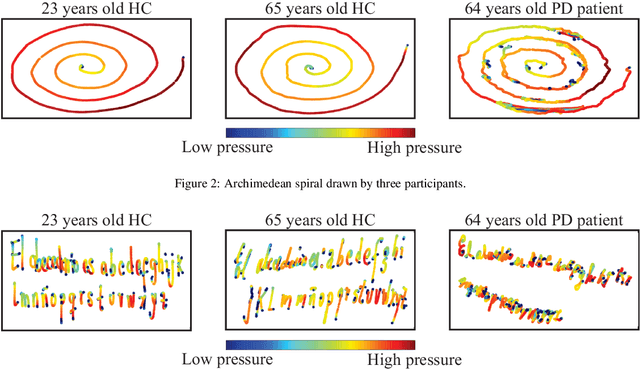
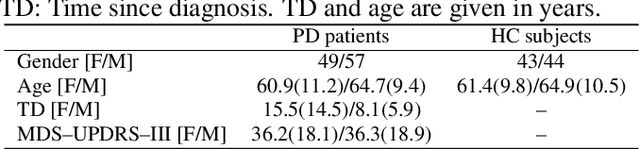
Background and objectives: Parkinson's disease is a neurological disorder that affects the motor system producing lack of coordination, resting tremor, and rigidity. Impairments in handwriting are among the main symptoms of the disease. Handwriting analysis can help in supporting the diagnosis and in monitoring the progress of the disease. This paper aims to evaluate the importance of different groups of features to model handwriting deficits that appear due to Parkinson's disease; and how those features are able to discriminate between Parkinson's disease patients and healthy subjects. Methods: Features based on kinematic, geometrical and non-linear dynamics analyses were evaluated to classify Parkinson's disease and healthy subjects. Classifiers based on K-nearest neighbors, support vector machines, and random forest were considered. Results: Accuracies of up to $93.1\%$ were obtained in the classification of patients and healthy control subjects. A relevance analysis of the features indicated that those related to speed, acceleration, and pressure are the most discriminant. The automatic classification of patients in different stages of the disease shows $\kappa$ indexes between $0.36$ and $0.44$. Accuracies of up to $83.3\%$ were obtained in a different dataset used only for validation purposes. Conclusions: The results confirmed the negative impact of aging in the classification process when we considered different groups of healthy subjects. In addition, the results reported with the separate validation set comprise a step towards the development of automated tools to support the diagnosis process in clinical practice.
Convolutional Neural Networks and a Transfer Learning Strategy to Classify Parkinson's Disease from Speech in Three Different Languages
Feb 11, 2020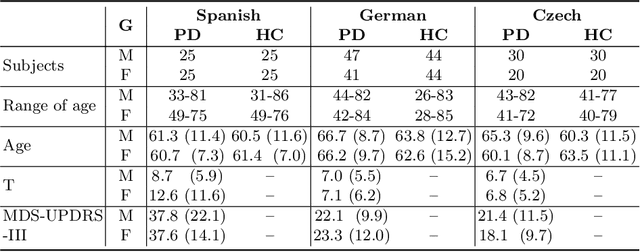
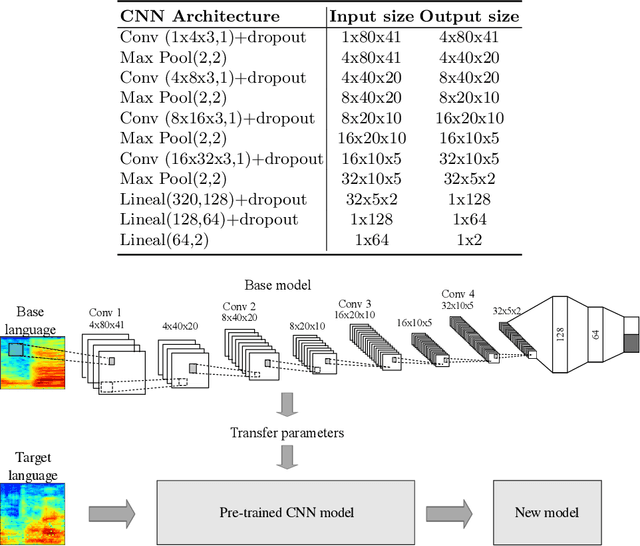
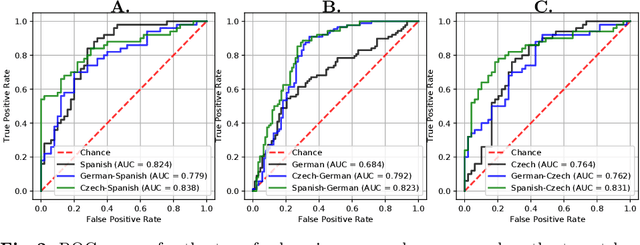

Parkinson's disease patients develop different speech impairments that affect their communication capabilities. The automatic assessment of the speech of the patients allows the development of computer aided tools to support the diagnosis and the evaluation of the disease severity. This paper introduces a methodology to classify Parkinson's disease from speech in three different languages: Spanish, German, and Czech. The proposed approach considers convolutional neural networks trained with time frequency representations and a transfer learning strategy among the three languages. The transfer learning scheme aims to improve the accuracy of the models when the weights of the neural network are initialized with utterances from a different language than the used for the test set. The results suggest that the proposed strategy improves the accuracy of the models in up to 8\% when the base model used to initialize the weights of the classifier is robust enough. In addition, the results obtained after the transfer learning are in most cases more balanced in terms of specificity-sensitivity than those trained without the transfer learning strategy.