 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConjoined Dirichlet Process
Feb 08, 2020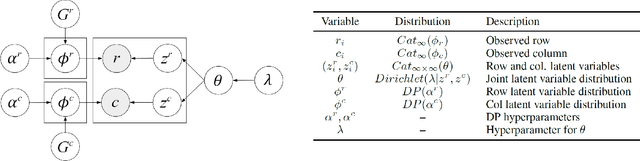



Biclustering is a class of techniques that simultaneously clusters the rows and columns of a matrix to sort heterogeneous data into homogeneous blocks. Although many algorithms have been proposed to find biclusters, existing methods suffer from the pre-specification of the number of biclusters or place constraints on the model structure. To address these issues, we develop a novel, non-parametric probabilistic biclustering method based on Dirichlet processes to identify biclusters with strong co-occurrence in both rows and columns. The proposed method utilizes dual Dirichlet process mixture models to learn row and column clusters, with the number of resulting clusters determined by the data rather than pre-specified. Probabilistic biclusters are identified by modeling the mutual dependence between the row and column clusters. We apply our method to two different applications, text mining and gene expression analysis, and demonstrate that our method improves bicluster extraction in many settings compared to existing approaches.