 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVision-Language Integration in Multimodal Video Transformers (Partially) Aligns with the Brain
Nov 13, 2023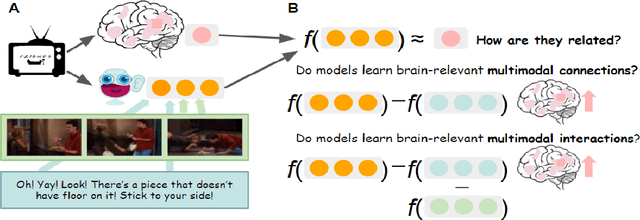



Integrating information from multiple modalities is arguably one of the essential prerequisites for grounding artificial intelligence systems with an understanding of the real world. Recent advances in video transformers that jointly learn from vision, text, and sound over time have made some progress toward this goal, but the degree to which these models integrate information from modalities still remains unclear. In this work, we present a promising approach for probing a pre-trained multimodal video transformer model by leveraging neuroscientific evidence of multimodal information processing in the brain. Using brain recordings of participants watching a popular TV show, we analyze the effects of multi-modal connections and interactions in a pre-trained multi-modal video transformer on the alignment with uni- and multi-modal brain regions. We find evidence that vision enhances masked prediction performance during language processing, providing support that cross-modal representations in models can benefit individual modalities. However, we don't find evidence of brain-relevant information captured by the joint multi-modal transformer representations beyond that captured by all of the individual modalities. We finally show that the brain alignment of the pre-trained joint representation can be improved by fine-tuning using a task that requires vision-language inferences. Overall, our results paint an optimistic picture of the ability of multi-modal transformers to integrate vision and language in partially brain-relevant ways but also show that improving the brain alignment of these models may require new approaches.