 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCotatron: Transcription-Guided Speech Encoder for Any-to-Many Voice Conversion without Parallel Data
May 07, 2020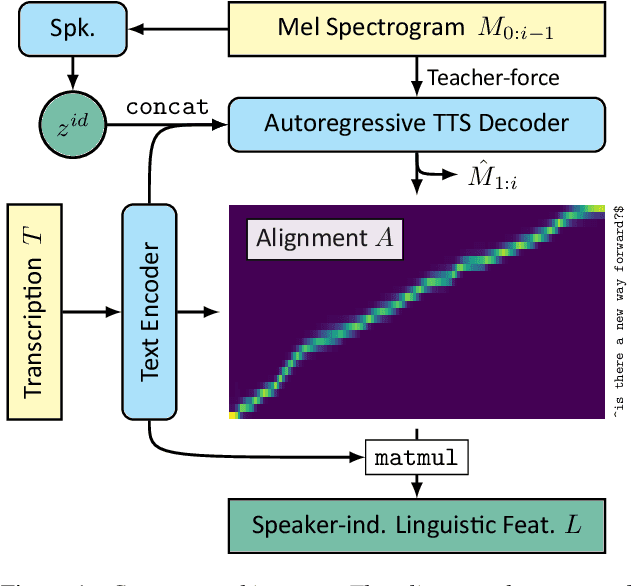
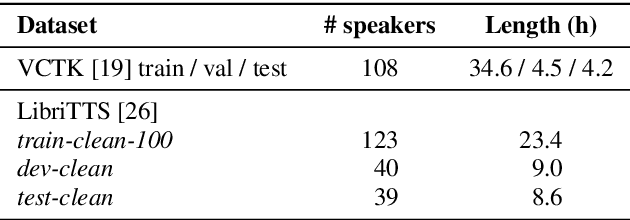
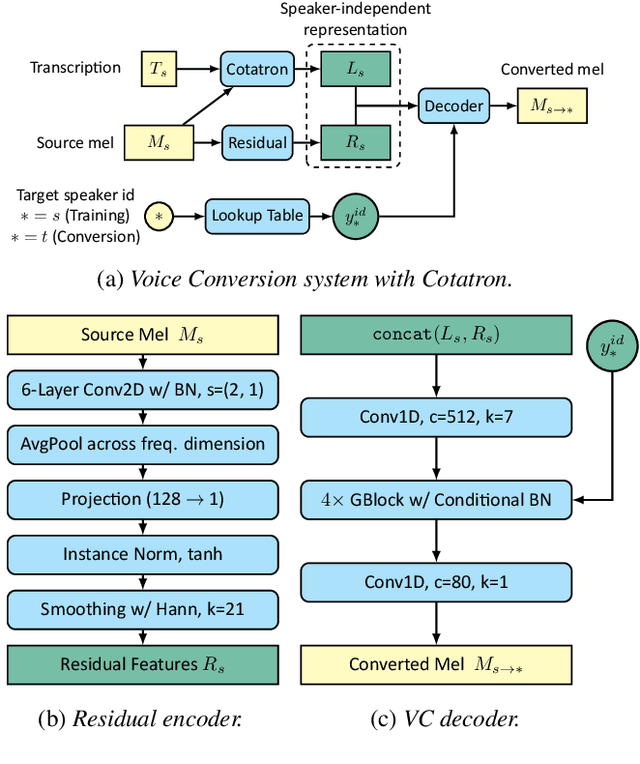
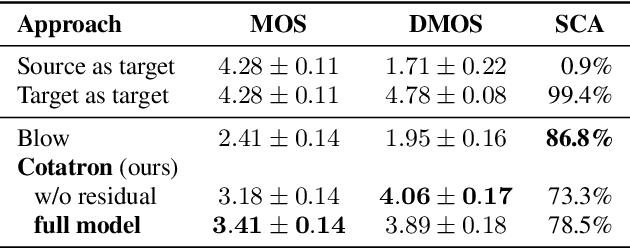
We propose Cotatron, a transcription-guided speech encoder for speaker-independent linguistic representation. Cotatron is based on the multispeaker TTS architecture and can be trained with conventional TTS datasets. We train a voice conversion system to reconstruct speech with Cotatron features, which is similar to the previous methods based on Phonetic Posteriorgram (PPG). By training and evaluating our system with 108 speakers from the VCTK dataset, we outperform the previous method in terms of both naturalness and speaker similarity. Our system can also convert speech from speakers that are unseen during training, and utilize ASR to automate the transcription with minimal reduction of the performance. Audio samples are available at https://mindslab-ai.github.io/cotatron, and the code with a pre-trained model will be made available soon.