 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating the Analysis of Public Saliency and Attitudes towards Biodiversity from Digital Media
May 02, 2024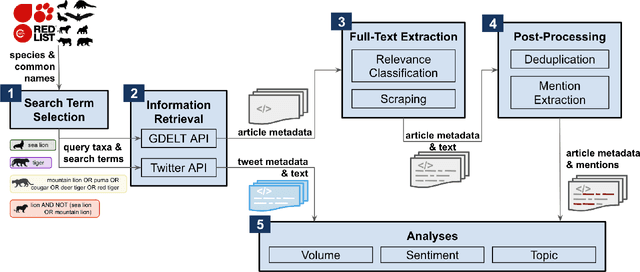
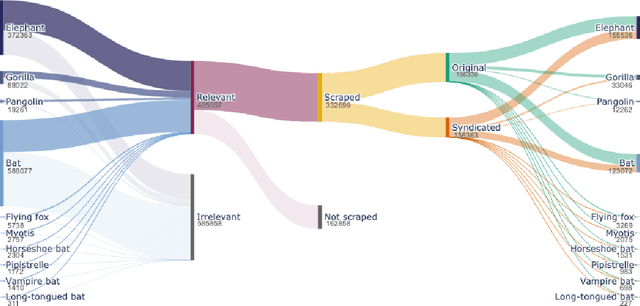
Measuring public attitudes toward wildlife provides crucial insights into our relationship with nature and helps monitor progress toward Global Biodiversity Framework targets. Yet, conducting such assessments at a global scale is challenging. Manually curating search terms for querying news and social media is tedious, costly, and can lead to biased results. Raw news and social media data returned from queries are often cluttered with irrelevant content and syndicated articles. We aim to overcome these challenges by leveraging modern Natural Language Processing (NLP) tools. We introduce a folk taxonomy approach for improved search term generation and employ cosine similarity on Term Frequency-Inverse Document Frequency vectors to filter syndicated articles. We also introduce an extensible relevance filtering pipeline which uses unsupervised learning to reveal common topics, followed by an open-source zero-shot Large Language Model (LLM) to assign topics to news article titles, which are then used to assign relevance. Finally, we conduct sentiment, topic, and volume analyses on resulting data. We illustrate our methodology with a case study of news and X (formerly Twitter) data before and during the COVID-19 pandemic for various mammal taxa, including bats, pangolins, elephants, and gorillas. During the data collection period, up to 62% of articles including keywords pertaining to bats were deemed irrelevant to biodiversity, underscoring the importance of relevance filtering. At the pandemic's onset, we observed increased volume and a significant sentiment shift toward horseshoe bats, which were implicated in the pandemic, but not for other focal taxa. The proposed methods open the door to conservation practitioners applying modern and emerging NLP tools, including LLMs "out of the box," to analyze public perceptions of biodiversity during current events or campaigns.