 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePointTransformer for Shape Classification and Retrieval of 3D and ALS Roof PointClouds
Nov 08, 2020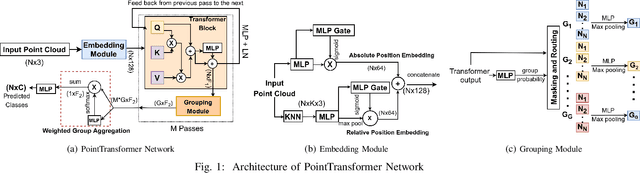

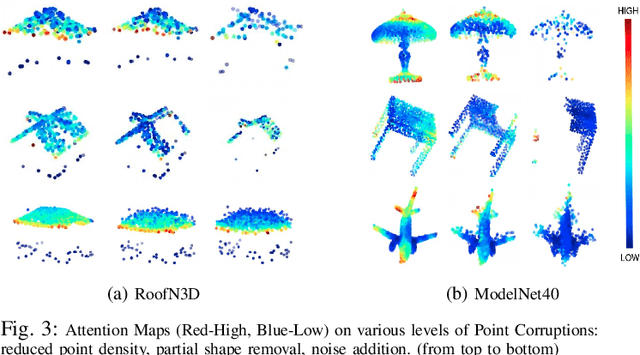
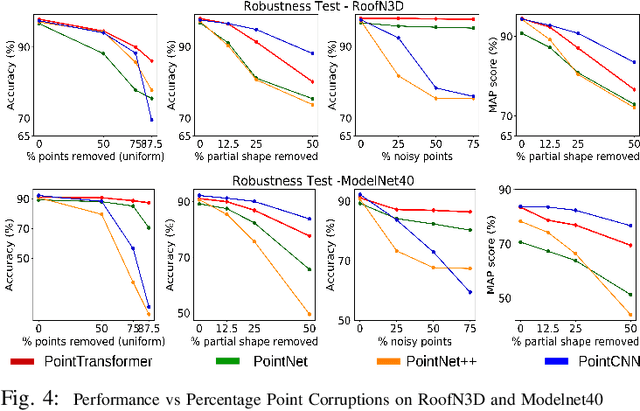
Effective feature representation from Airborne Laser Scanning (ALS) point clouds used for urban modeling was challenging until the advent of deep learning and improved ALS techniques. Most deep learning techniques for 3-D point clouds utilize convolutions that assume a uniform input distribution and cannot learn long-range dependencies, leading to some limitations. Recent works have already shown that adding attention on top of these methods improves performance. This raises a question: can attention layers completely replace convolutions? We propose a fully attentional model-PointTransformer for deriving a rich point cloud representation. The model's shape classification and retrieval performance are evaluated on a large-scale urban dataset - RoofN3D and a standard benchmark dataset ModelNet40. Also, the model is tested on various simulated point corruptions to analyze its effectiveness on real datasets. The proposed method outperforms other state-of-the-art models in the RoofN3D dataset, gives competitive results in the ModelNet40 benchmark, and showcases high robustness to multiple point corruptions. Furthermore, the model is both memory and space-efficient without compromising on performance.