 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAMOTS: A Real-Time System for Aerial Multi-Object Tracking based on Deep Learning and Big Data Technology
Feb 06, 2025



Multi-object tracking (MOT) in UAV-based video is challenging due to variations in viewpoint, low resolution, and the presence of small objects. While other research on MOT dedicated to aerial videos primarily focuses on the academic aspect by developing sophisticated algorithms, there is a lack of attention to the practical aspect of these systems. In this paper, we propose a novel real-time MOT framework that integrates Apache Kafka and Apache Spark for efficient and fault-tolerant video stream processing, along with state-of-the-art deep learning models YOLOv8/YOLOv10 and BYTETRACK/BoTSORT for accurate object detection and tracking. Our work highlights the importance of not only the advanced algorithms but also the integration of these methods with scalable and distributed systems. By leveraging these technologies, our system achieves a HOTA of 48.14 and a MOTA of 43.51 on the Visdrone2019-MOT test set while maintaining a real-time processing speed of 28 FPS on a single GPU. Our work demonstrates the potential of big data technologies and deep learning for addressing the challenges of MOT in UAV applications.
DS@BioMed at ImageCLEFmedical Caption 2024: Enhanced Attention Mechanisms in Medical Caption Generation through Concept Detection Integration
Jun 01, 2024
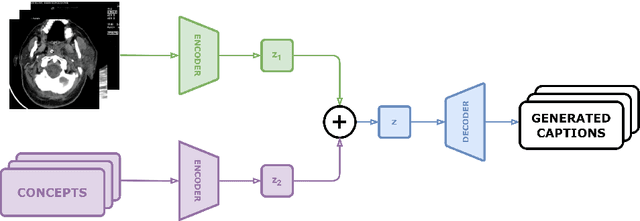
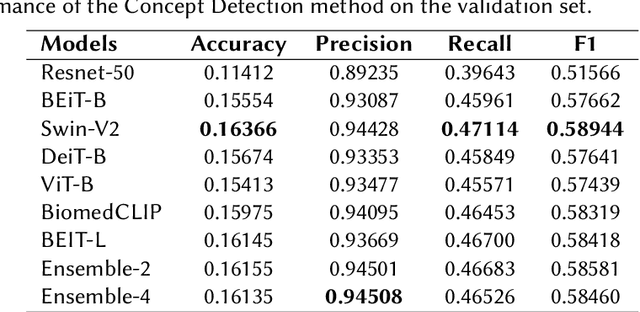
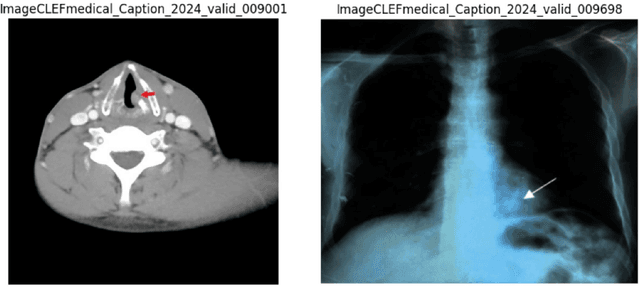
Purpose: Our study presents an enhanced approach to medical image caption generation by integrating concept detection into attention mechanisms. Method: This method utilizes sophisticated models to identify critical concepts within medical images, which are then refined and incorporated into the caption generation process. Results: Our concept detection task, which employed the Swin-V2 model, achieved an F1 score of 0.58944 on the validation set and 0.61998 on the private test set, securing the third position. For the caption prediction task, our BEiT+BioBart model, enhanced with concept integration and post-processing techniques, attained a BERTScore of 0.60589 on the validation set and 0.5794 on the private test set, placing ninth. Conclusion: These results underscore the efficacy of concept-aware algorithms in generating precise and contextually appropriate medical descriptions. The findings demonstrate that our approach significantly improves the quality of medical image captions, highlighting its potential to enhance medical image interpretation and documentation, thereby contributing to improved healthcare outcomes.