 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoVLM: Leveraging Consensus from Vision-Language Models for Semi-supervised Multi-modal Fake News Detection
Oct 06, 2024
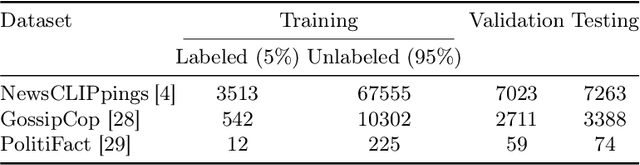
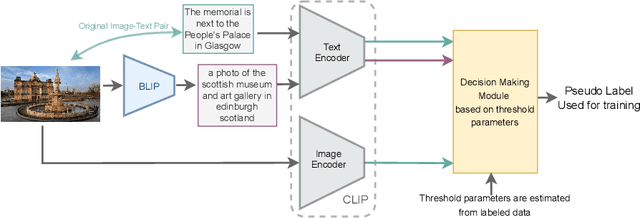
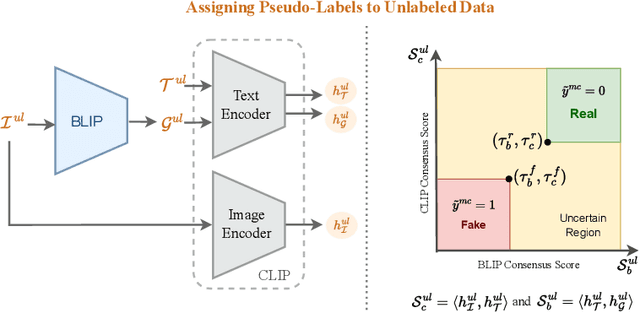
In this work, we address the real-world, challenging task of out-of-context misinformation detection, where a real image is paired with an incorrect caption for creating fake news. Existing approaches for this task assume the availability of large amounts of labeled data, which is often impractical in real-world, since it requires extensive manual intervention and domain expertise. In contrast, since obtaining a large corpus of unlabeled image-text pairs is much easier, here, we propose a semi-supervised protocol, where the model has access to a limited number of labeled image-text pairs and a large corpus of unlabeled pairs. Additionally, the occurrence of fake news being much lesser compared to the real ones, the datasets tend to be highly imbalanced, thus making the task even more challenging. Towards this goal, we propose a novel framework, Consensus from Vision-Language Models (CoVLM), which generates robust pseudo-labels for unlabeled pairs using thresholds derived from the labeled data. This approach can automatically determine the right threshold parameters of the model for selecting the confident pseudo-labels. Experimental results on benchmark datasets across challenging conditions and comparisons with state-of-the-art approaches demonstrate the effectiveness of our framework.