Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDetecting Label Errors using Pre-Trained Language Models
May 25, 2022


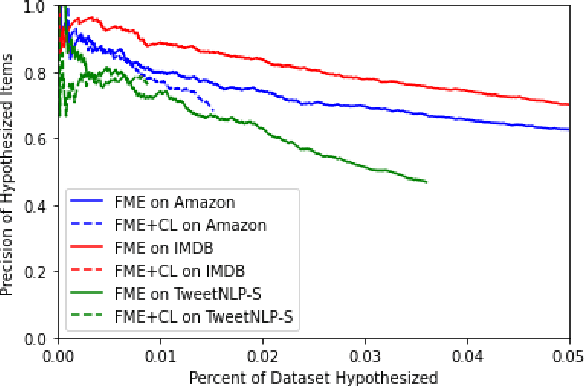
We show that large pre-trained language models are extremely capable of identifying label errors in datasets: simply verifying data points in descending order of out-of-distribution loss significantly outperforms more complex mechanisms for detecting label errors on natural language datasets. We contribute a novel method to produce highly realistic, human-originated label noise from crowdsourced data, and demonstrate the effectiveness of this method on TweetNLP, providing an otherwise difficult to obtain measure of realistic recall.
Via