 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImagiNet: A Multi-Content Dataset for Generalizable Synthetic Image Detection via Contrastive Learning
Jul 29, 2024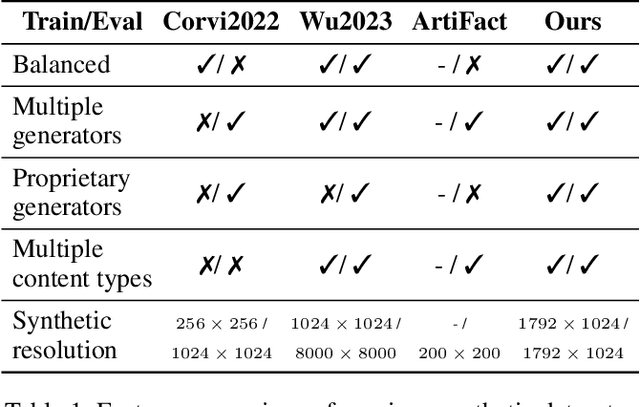

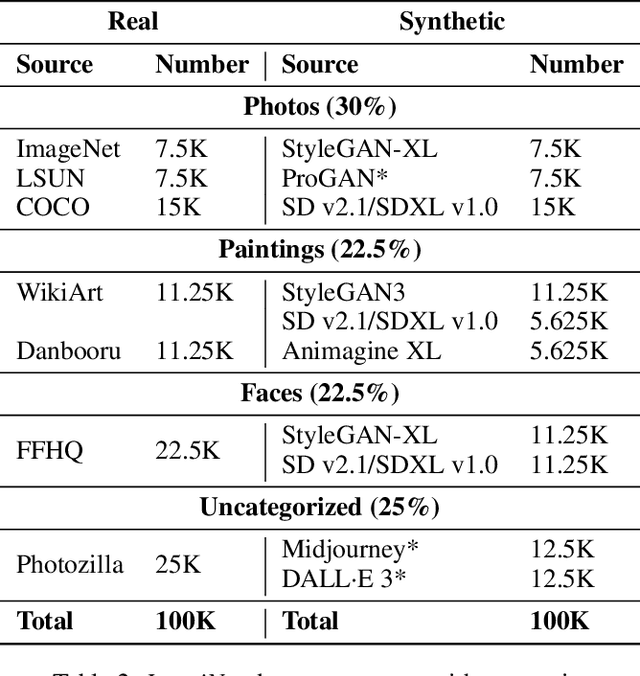
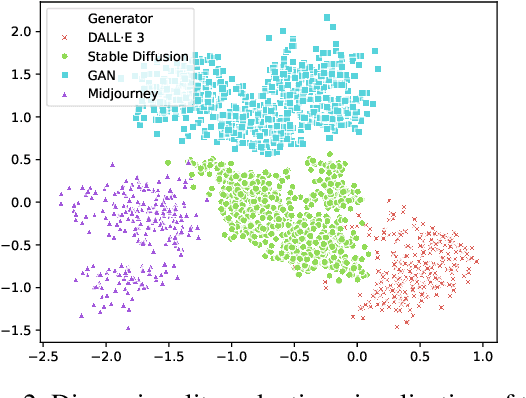
Generative models, such as diffusion models (DMs), variational autoencoders (VAEs), and generative adversarial networks (GANs), produce images with a level of authenticity that makes them nearly indistinguishable from real photos and artwork. While this capability is beneficial for many industries, the difficulty of identifying synthetic images leaves online media platforms vulnerable to impersonation and misinformation attempts. To support the development of defensive methods, we introduce ImagiNet, a high-resolution and balanced dataset for synthetic image detection, designed to mitigate potential biases in existing resources. It contains 200K examples, spanning four content categories: photos, paintings, faces, and uncategorized. Synthetic images are produced with open-source and proprietary generators, whereas real counterparts of the same content type are collected from public datasets. The structure of ImagiNet allows for a two-track evaluation system: i) classification as real or synthetic and ii) identification of the generative model. To establish a baseline, we train a ResNet-50 model using a self-supervised contrastive objective (SelfCon) for each track. The model demonstrates state-of-the-art performance and high inference speed across established benchmarks, achieving an AUC of up to 0.99 and balanced accuracy ranging from 86% to 95%, even under social network conditions that involve compression and resizing. Our data and code are available at https://github.com/delyan-boychev/imaginet.
Interpretable Computer Vision Models through Adversarial Training: Unveiling the Robustness-Interpretability Connection
Jul 04, 2023



With the perpetual increase of complexity of the state-of-the-art deep neural networks, it becomes a more and more challenging task to maintain their interpretability. Our work aims to evaluate the effects of adversarial training utilized to produce robust models - less vulnerable to adversarial attacks. It has been shown to make computer vision models more interpretable. Interpretability is as essential as robustness when we deploy the models to the real world. To prove the correlation between these two problems, we extensively examine the models using local feature-importance methods (SHAP, Integrated Gradients) and feature visualization techniques (Representation Inversion, Class Specific Image Generation). Standard models, compared to robust are more susceptible to adversarial attacks, and their learned representations are less meaningful to humans. Conversely, these models focus on distinctive regions of the images which support their predictions. Moreover, the features learned by the robust model are closer to the real ones.