Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperimental Design for Bathymetry Editing
Jul 15, 2020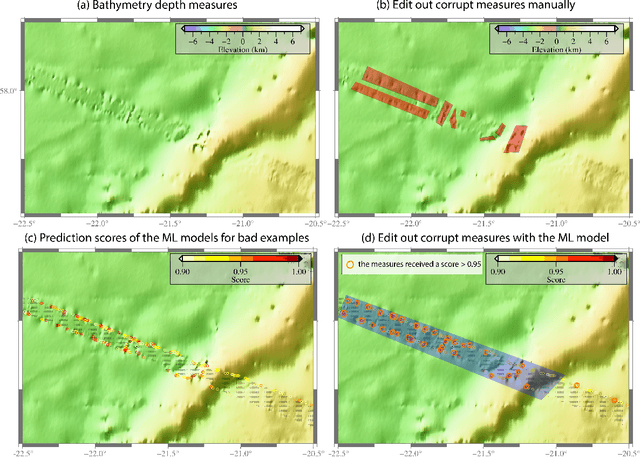
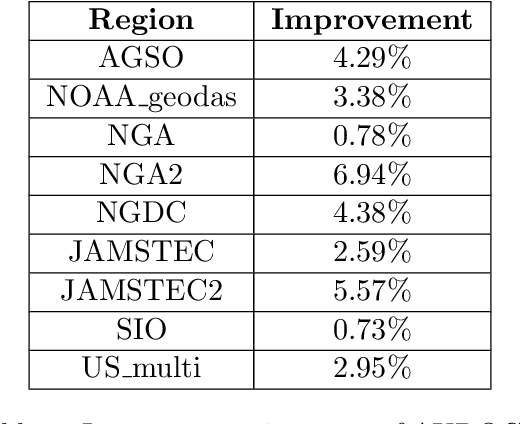
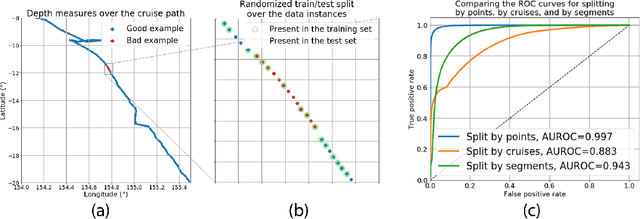
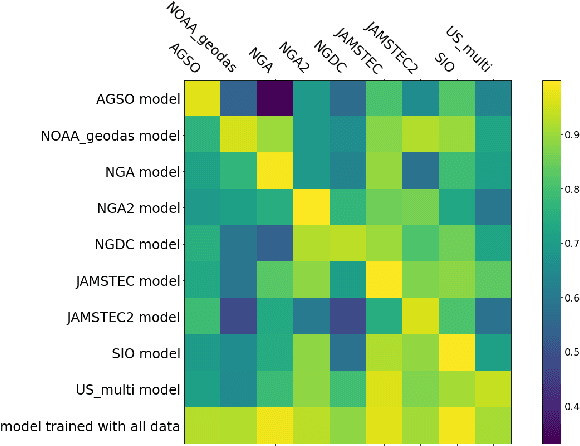
We describe an application of machine learning to a real-world computer assisted labeling task. Our experimental results expose significant deviations from the IID assumption commonly used in machine learning. These results suggest that the common random split of all data into training and testing can often lead to poor performance.
* Published as a workshop paper at ICML 2020 Workshop on Real World
Experiment Design and Active Learning
Via