 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeepCVA: Automated Commit-level Vulnerability Assessment with Deep Multi-task Learning
Aug 18, 2021
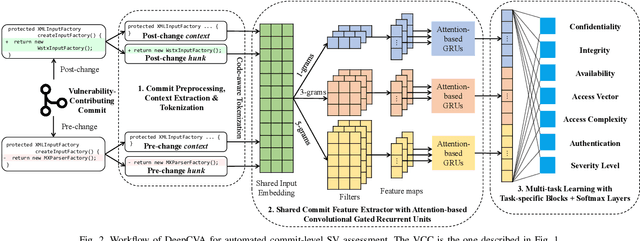

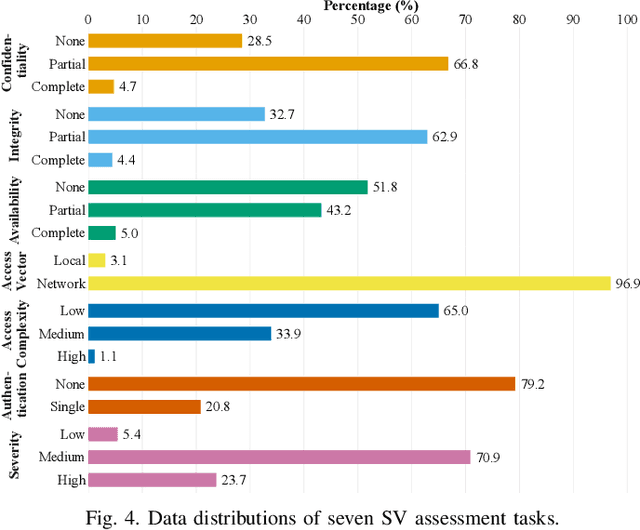
It is increasingly suggested to identify Software Vulnerabilities (SVs) in code commits to give early warnings about potential security risks. However, there is a lack of effort to assess vulnerability-contributing commits right after they are detected to provide timely information about the exploitability, impact and severity of SVs. Such information is important to plan and prioritize the mitigation for the identified SVs. We propose a novel Deep multi-task learning model, DeepCVA, to automate seven Commit-level Vulnerability Assessment tasks simultaneously based on Common Vulnerability Scoring System (CVSS) metrics. We conduct large-scale experiments on 1,229 vulnerability-contributing commits containing 542 different SVs in 246 real-world software projects to evaluate the effectiveness and efficiency of our model. We show that DeepCVA is the best-performing model with 38% to 59.8% higher Matthews Correlation Coefficient than many supervised and unsupervised baseline models. DeepCVA also requires 6.3 times less training and validation time than seven cumulative assessment models, leading to significantly less model maintenance cost as well. Overall, DeepCVA presents the first effective and efficient solution to automatically assess SVs early in software systems.
StackOverflow vs Kaggle: A Study of Developer Discussions About Data Science
Jun 06, 2020


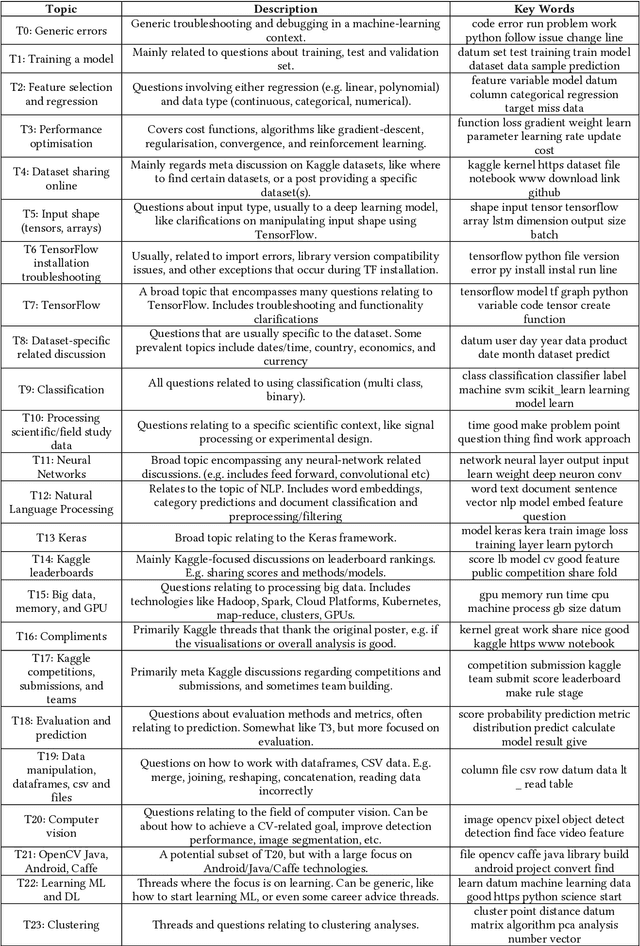
Software developers are increasingly required to understand fundamental Data science (DS) concepts. Recently, the presence of machine learning (ML) and deep learning (DL) has dramatically increased in the development of user applications, whether they are leveraged through frameworks or implemented from scratch. These topics attract much discussion on online platforms. This paper conducts large-scale qualitative and quantitative experiments to study the characteristics of 197836 posts from StackOverflow and Kaggle. Latent Dirichlet Allocation topic modelling is used to extract twenty-four DS discussion topics. The main findings include that TensorFlow-related topics were most prevalent in StackOverflow, while meta discussion topics were the prevalent ones on Kaggle. StackOverflow tends to include lower-level troubleshooting, while Kaggle focuses on practicality and optimising leaderboard performance. In addition, across both communities, DS discussion is increasing at a dramatic rate. While TensorFlow discussion on StackOverflow is slowing, interest in Keras is rising. Finally, ensemble algorithms are the most mentioned ML/DL algorithms in Kaggle but are rarely discussed on StackOverflow. These findings can help educators and researchers to more effectively tailor and prioritise efforts in researching and communicating DS concepts towards different developer communities.
PUMiner: Mining Security Posts from Developer Question and Answer Websites with PU Learning
Mar 08, 2020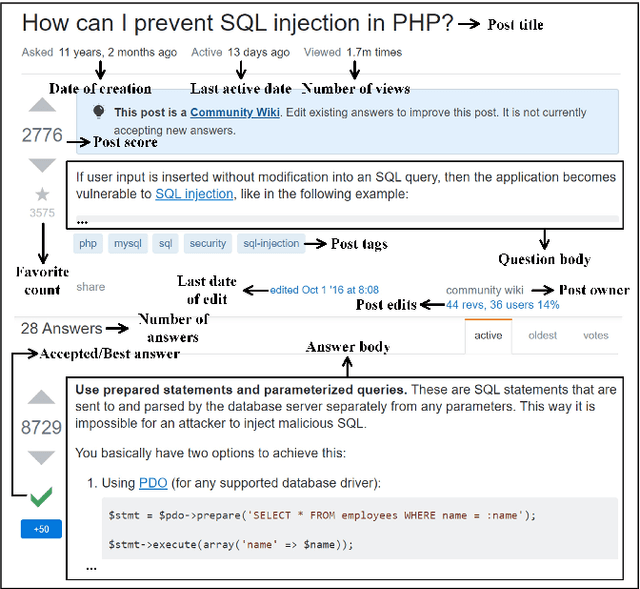
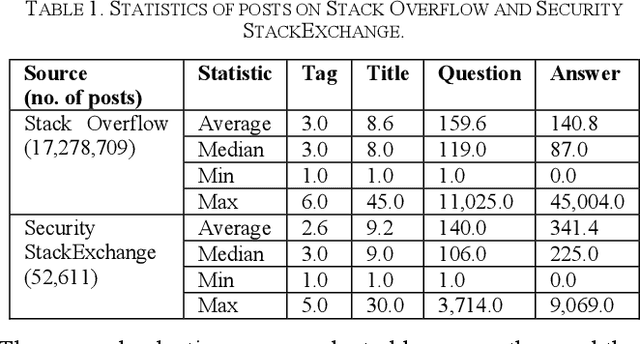
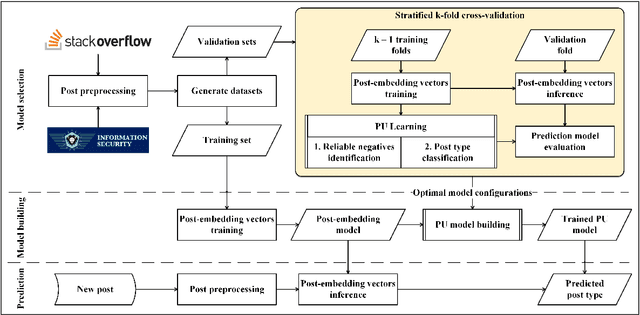
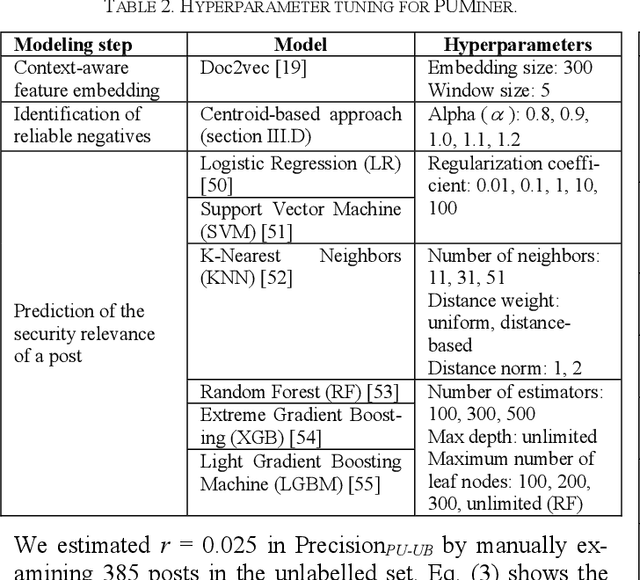
Security is an increasing concern in software development. Developer Question and Answer (Q&A) websites provide a large amount of security discussion. Existing studies have used human-defined rules to mine security discussions, but these works still miss many posts, which may lead to an incomplete analysis of the security practices reported on Q&A websites. Traditional supervised Machine Learning methods can automate the mining process; however, the required negative (non-security) class is too expensive to obtain. We propose a novel learning framework, PUMiner, to automatically mine security posts from Q&A websites. PUMiner builds a context-aware embedding model to extract features of the posts, and then develops a two-stage PU model to identify security content using the labelled Positive and Unlabelled posts. We evaluate PUMiner on more than 17.2 million posts on Stack Overflow and 52,611 posts on Security StackExchange. We show that PUMiner is effective with the validation performance of at least 0.85 across all model configurations. Moreover, Matthews Correlation Coefficient (MCC) of PUMiner is 0.906, 0.534 and 0.084 points higher than one-class SVM, positive-similarity filtering, and one-stage PU models on unseen testing posts, respectively. PUMiner also performs well with an MCC of 0.745 for scenarios where string matching totally fails. Even when the ratio of the labelled positive posts to the unlabelled ones is only 1:100, PUMiner still achieves a strong MCC of 0.65, which is 160% better than fully-supervised learning. Using PUMiner, we provide the largest and up-to-date security content on Q&A websites for practitioners and researchers.