 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Stolenly Swear That I Am Up to (No) Good: Design and Evaluation of Model Stealing Attacks
Aug 29, 2025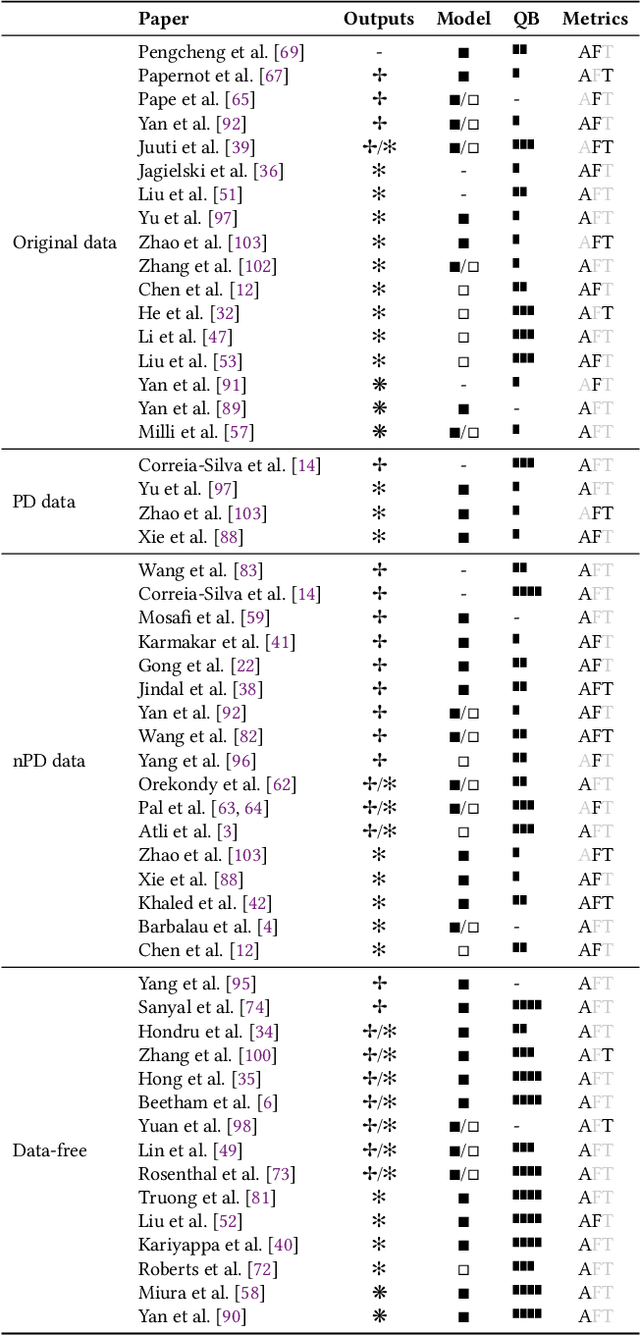
Model stealing attacks endanger the confidentiality of machine learning models offered as a service. Although these models are kept secret, a malicious party can query a model to label data samples and train their own substitute model, violating intellectual property. While novel attacks in the field are continually being published, their design and evaluations are not standardised, making it challenging to compare prior works and assess progress in the field. This paper is the first to address this gap by providing recommendations for designing and evaluating model stealing attacks. To this end, we study the largest group of attacks that rely on training a substitute model -- those attacking image classification models. We propose the first comprehensive threat model and develop a framework for attack comparison. Further, we analyse attack setups from related works to understand which tasks and models have been studied the most. Based on our findings, we present best practices for attack development before, during, and beyond experiments and derive an extensive list of open research questions regarding the evaluation of model stealing attacks. Our findings and recommendations also transfer to other problem domains, hence establishing the first generic evaluation methodology for model stealing attacks.
Attackers Can Do Better: Over- and Understated Factors of Model Stealing Attacks
Mar 08, 2025
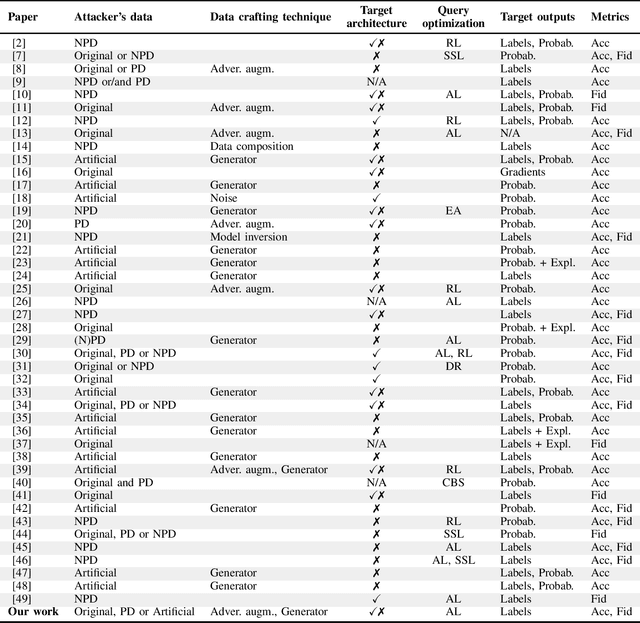
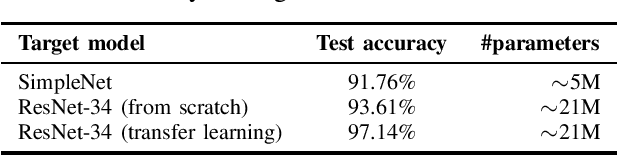
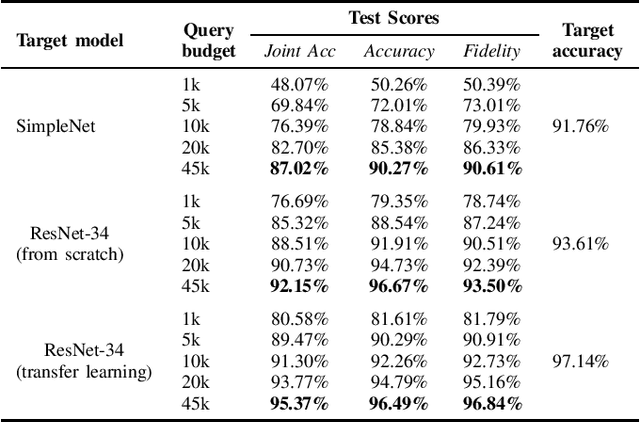
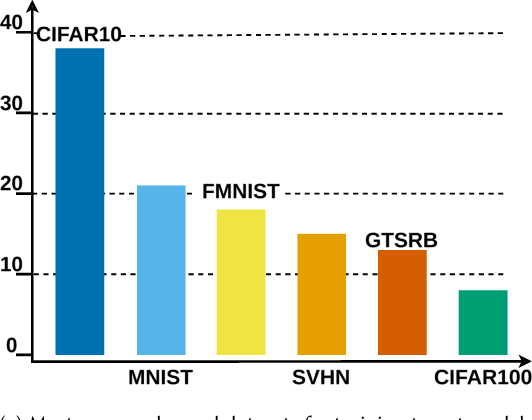
Machine learning models were shown to be vulnerable to model stealing attacks, which lead to intellectual property infringement. Among other methods, substitute model training is an all-encompassing attack applicable to any machine learning model whose behaviour can be approximated from input-output queries. Whereas prior works mainly focused on improving the performance of substitute models by, e.g. developing a new substitute training method, there have been only limited ablation studies on the impact the attacker's strength has on the substitute model's performance. As a result, different authors came to diverse, sometimes contradicting, conclusions. In this work, we exhaustively examine the ambivalent influence of different factors resulting from varying the attacker's capabilities and knowledge on a substitute training attack. Our findings suggest that some of the factors that have been considered important in the past are, in fact, not that influential; instead, we discover new correlations between attack conditions and success rate. In particular, we demonstrate that better-performing target models enable higher-fidelity attacks and explain the intuition behind this phenomenon. Further, we propose to shift the focus from the complexity of target models toward the complexity of their learning tasks. Therefore, for the substitute model, rather than aiming for a higher architecture complexity, we suggest focusing on getting data of higher complexity and an appropriate architecture. Finally, we demonstrate that even in the most limited data-free scenario, there is no need to overcompensate weak knowledge with millions of queries. Our results often exceed or match the performance of previous attacks that assume a stronger attacker, suggesting that these stronger attacks are likely endangering a model owner's intellectual property to a significantly higher degree than shown until now.
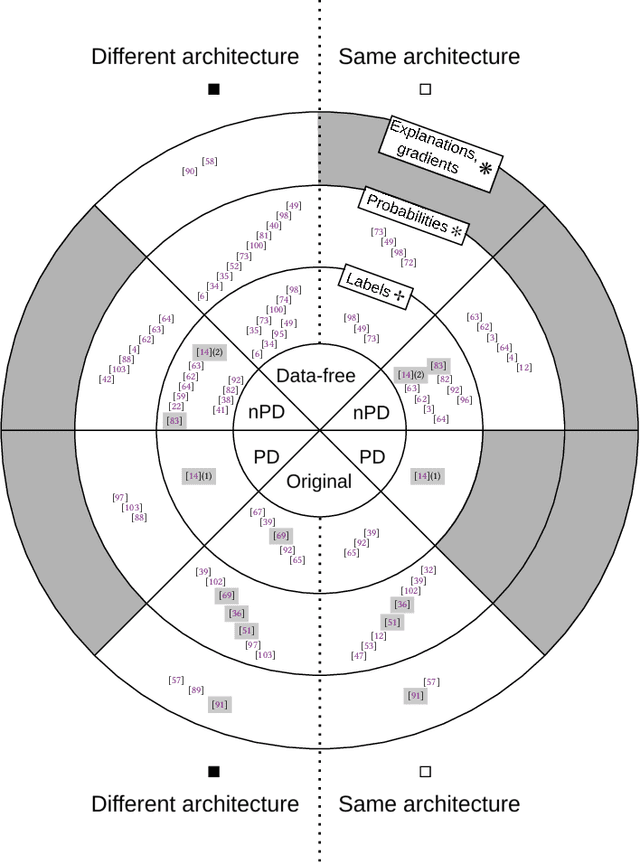
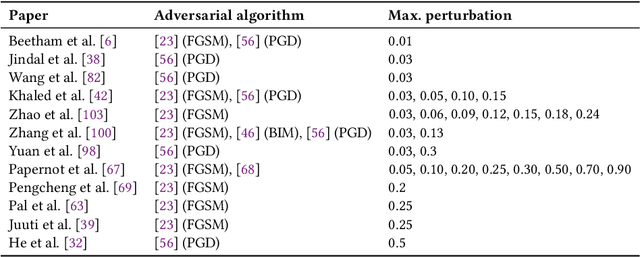
I Know What You Trained Last Summer: A Survey on Stealing Machine Learning Models and Defences
Jun 16, 2022



Machine Learning-as-a-Service (MLaaS) has become a widespread paradigm, making even the most complex machine learning models available for clients via e.g. a pay-per-query principle. This allows users to avoid time-consuming processes of data collection, hyperparameter tuning, and model training. However, by giving their customers access to the (predictions of their) models, MLaaS providers endanger their intellectual property, such as sensitive training data, optimised hyperparameters, or learned model parameters. Adversaries can create a copy of the model with (almost) identical behavior using the the prediction labels only. While many variants of this attack have been described, only scattered defence strategies have been proposed, addressing isolated threats. This raises the necessity for a thorough systematisation of the field of model stealing, to arrive at a comprehensive understanding why these attacks are successful, and how they could be holistically defended against. We address this by categorising and comparing model stealing attacks, assessing their performance, and exploring corresponding defence techniques in different settings. We propose a taxonomy for attack and defence approaches, and provide guidelines on how to select the right attack or defence strategy based on the goal and available resources. Finally, we analyse which defences are rendered less effective by current attack strategies.