 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForesight Learning for SEC Risk Prediction
Jan 27, 2026Risk disclosures in SEC filings describe potential adverse events but rarely quantify their likelihood, limiting their usefulness for probabilistic analysis. A central obstacle is the absence of large-scale, risk-level supervision linking disclosed risks to realized outcomes. We introduce a fully automated data generation pipeline that converts qualitative SEC risk disclosures into temporally grounded supervision using only public data. For each filing, the pipeline generates firm-specific, time-bounded risk queries from the Risk Factors section and labels them by automatically resolving outcomes against subsequent disclosures. Using this dataset of risk queries and outcomes grounded in SEC filings, we train a compact large language model to estimate the probability that a disclosed risk will materialize within a specified horizon. Despite its modest size, the resulting model substantially improves over pretrained and heuristic baselines, and outperforms frontier general-purpose models, including GPT-5, on probabilistic accuracy and calibration. More broadly, this work demonstrates that Foresight Learning enables scalable and fully automated training of domain-specific expert models using only raw, chronological, in-domain text -- without proprietary data, external corpora, or manual annotation. The resulting models achieve frontier-level performance while remaining deployable on a single GPU. This result suggests a general pathway for learning calibrated, decision-relevant signals from naturally occurring enterprise documents. To support transparency and reproducibility, we open-source the evaluation dataset used in this study. Evaluation Data: https://huggingface.co/datasets/LightningRodLabs/sec_risk_questions_test_set Data Generation Platform: https://lightningrod.ai/ SDK: https://github.com/lightning-rod-labs/lightningrod-python-sdk
Future-as-Label: Scalable Supervision from Real-World Outcomes
Jan 09, 2026Many real-world prediction problems lack labels observable at prediction time, creating a temporal gap between prediction and outcome that yields supervision only after events resolve. To address this setting, we extend reinforcement learning with verifiable rewards to temporally resolved real-world prediction, and use it to train language models to make probabilistic forecasts under causally masked information with retrospective evaluation using proper scoring rules. Supervision is derived solely from post-resolution outcomes, preserving delayed-reward semantics. On real-world forecasting benchmarks, Qwen3-32B trained using Foresight Learning improves Brier score by 27% and halves calibration error relative to its pretrained baseline, and outperforms Qwen3-235B on both constructed future-event prediction tasks and the Metaculus benchmark despite a 7x parameter disadvantage.
Outcome-based Reinforcement Learning to Predict the Future
May 26, 2025
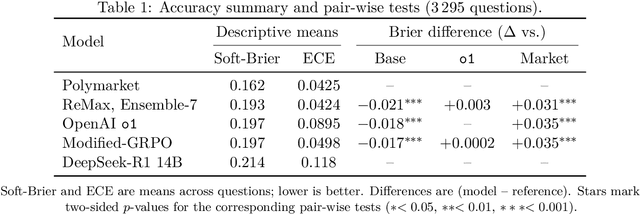
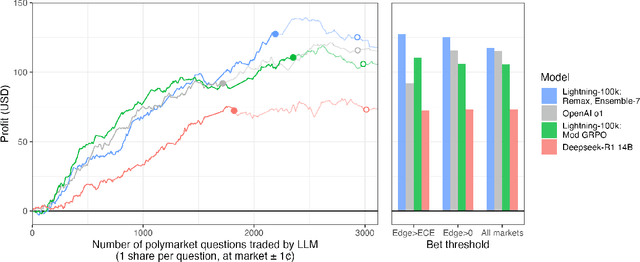

Reinforcement learning with verifiable rewards (RLVR) has boosted math and coding in large language models, yet there has been little effort to extend RLVR into messier, real-world domains like forecasting. One sticking point is that outcome-based reinforcement learning for forecasting must learn from binary, delayed, and noisy rewards, a regime where standard fine-tuning is brittle. We show that outcome-only online RL on a 14B model can match frontier-scale accuracy and surpass it in calibration and hypothetical prediction market betting by adapting two leading algorithms, Group-Relative Policy Optimisation (GRPO) and ReMax, to the forecasting setting. Our adaptations remove per-question variance scaling in GRPO, apply baseline-subtracted advantages in ReMax, hydrate training with 100k temporally consistent synthetic questions, and introduce lightweight guard-rails that penalise gibberish, non-English responses and missing rationales, enabling a single stable pass over 110k events. Scaling ReMax to 110k questions and ensembling seven predictions yields a 14B model that matches frontier baseline o1 on accuracy on our holdout set (Brier = 0.193, p = 0.23) while beating it in calibration (ECE = 0.042, p < 0.001). A simple trading rule turns this calibration edge into \$127 of hypothetical profit versus \$92 for o1 (p = 0.037). This demonstrates that refined RLVR methods can convert small-scale LLMs into potentially economically valuable forecasting tools, with implications for scaling this to larger models.
LLMs Can Teach Themselves to Better Predict the Future
Feb 07, 2025We present an outcome-driven fine-tuning framework that enhances the forecasting capabilities of large language models (LLMs) without relying on human-curated reasoning samples. Our method leverages model self-play to generate pairs of diverse reasoning trajectories and probabilistic forecasts for a set of diverse questions that resolve after the models' knowledge cutoff date. We then rank pairs of these reasoning traces by their distance to the actual outcomes before fine-tuning the model via Direct Preference Optimization (DPO). On a separate test set, our approach increases prediction accuracy of Phi-4 14B and DeepSeek-R1 14B by between 7--10\% over a base model and a DPO fine-tuned control model with randomized labels, bringing them on par with forecasting capabilities of much larger frontier models like GPT-4o.