 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective inference for k-means clustering
Mar 29, 2022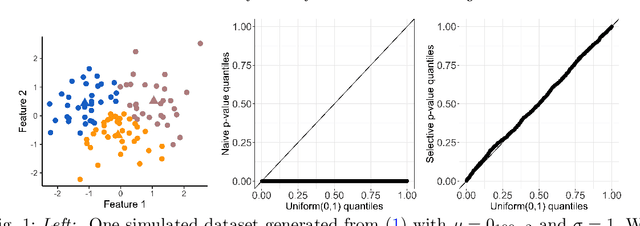
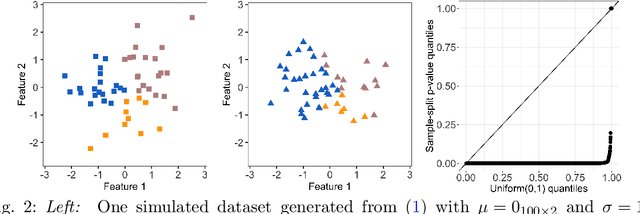
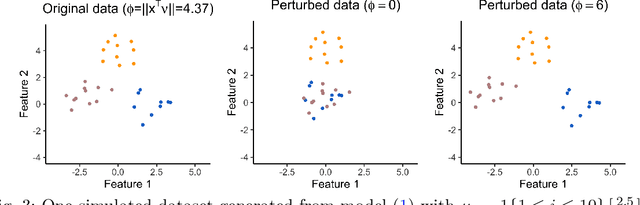
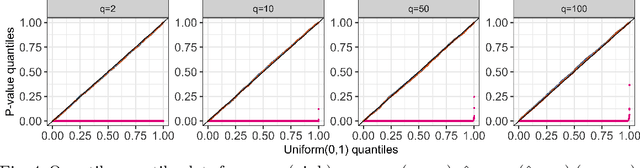
We consider the problem of testing for a difference in means between clusters of observations identified via k-means clustering. In this setting, classical hypothesis tests lead to an inflated Type I error rate. To overcome this problem, we take a selective inference approach. We propose a finite-sample p-value that controls the selective Type I error for a test of the difference in means between a pair of clusters obtained using k-means clustering, and show that it can be efficiently computed. We apply our proposal in simulation, and on hand-written digits data and single-cell RNA-sequencing data.
Tree-Values: selective inference for regression trees
Jun 15, 2021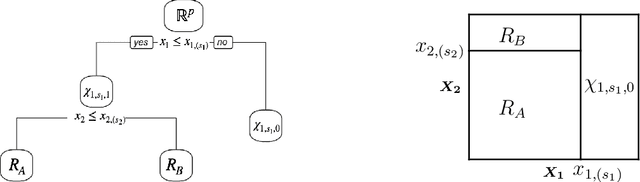

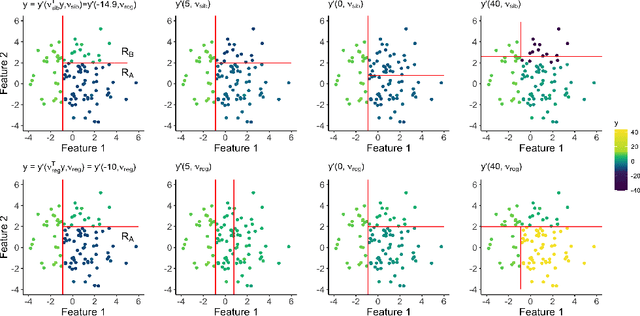

We consider conducting inference on the output of the Classification and Regression Tree (CART) [Breiman et al., 1984] algorithm. A naive approach to inference that does not account for the fact that the tree was estimated from the data will not achieve standard guarantees, such as Type 1 error rate control and nominal coverage. Thus, we propose a selective inference framework for conducting inference on a fitted CART tree. In a nutshell, we condition on the fact that the tree was estimated from the data. We propose a test for the difference in the mean response between a pair of terminal nodes that controls the selective Type 1 error rate, and a confidence interval for the mean response within a single terminal node that attains the nominal selective coverage. Efficient algorithms for computing the necessary conditioning sets are provided. We apply these methods in simulation and to a dataset involving the association between portion control interventions and caloric intake.