 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLabeler-hot Detection of EEG Epileptic Transients
Apr 02, 2019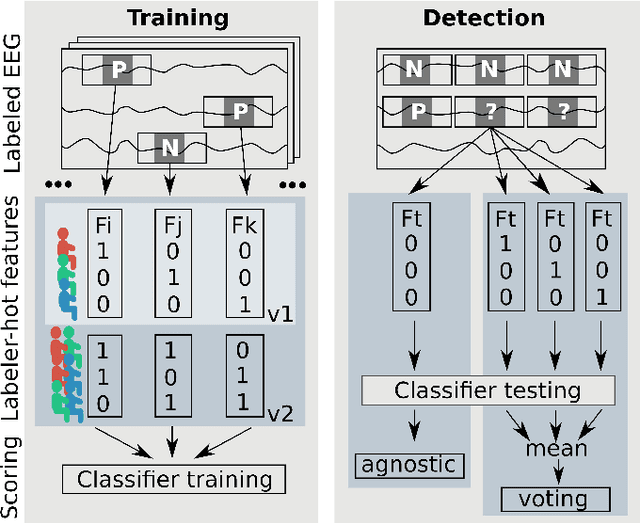
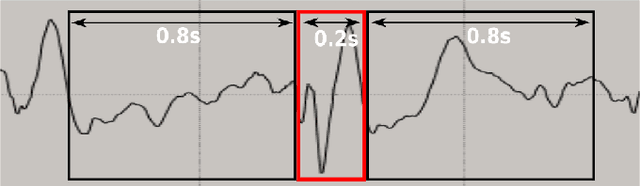
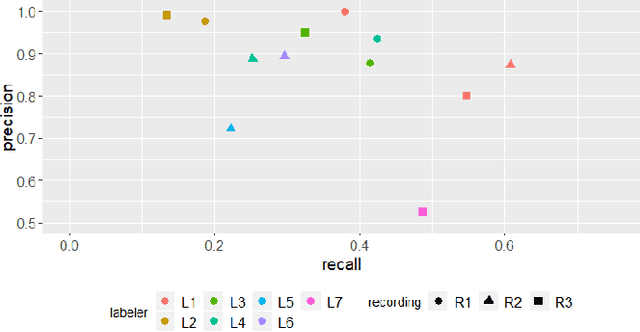

Preventing early progression of epilepsy and so the severity of seizures requires effective diagnosis. Epileptic transients indicate the ability to develop seizures but humans easily overlook such brief events in an electroencephalogram (EEG) what compromises patient treatment. Traditionally, training of the EEG event detection algorithms has relied on ground truth labels, obtained from the consensus of the majority of labelers. In this work, we go beyond labeler consensus on EEG data. Our event descriptor integrates EEG signal features with one-hot encoded labeler category that is a key to improved generalization performance. Notably, boosted decision trees take advantage of singly-labeled but more varied training sets. Our quantitative experiments show the proposed labeler-hot epileptic event detector consistently outperforms a consensus-trained detector and maintains confidence bounds of the detection. The results on our infant EEG recordings suggest datasets can gain higher event variety faster and thus better performance by shifting available human effort from consensus-oriented to separate labeling when labels include both, the event and the labeler category.
Exploring the Entire Regularization Path for the Asymmetric Cost Linear Support Vector Machine
Oct 12, 2016
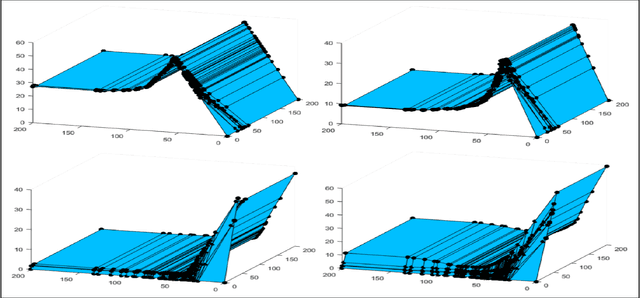
We propose an algorithm for exploring the entire regularization path of asymmetric-cost linear support vector machines. Empirical evidence suggests the predictive power of support vector machines depends on the regularization parameters of the training algorithms. The algorithms exploring the entire regularization paths have been proposed for single-cost support vector machines thereby providing the complete knowledge on the behavior of the trained model over the hyperparameter space. Considering the problem in two-dimensional hyperparameter space though enables our algorithm to maintain greater flexibility in dealing with special cases and sheds light on problems encountered by algorithms building the paths in one-dimensional spaces. We demonstrate two-dimensional regularization paths for linear support vector machines that we train on synthetic and real data.