Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuthorship Attribution Using the Chaos Game Representation
Feb 14, 2018

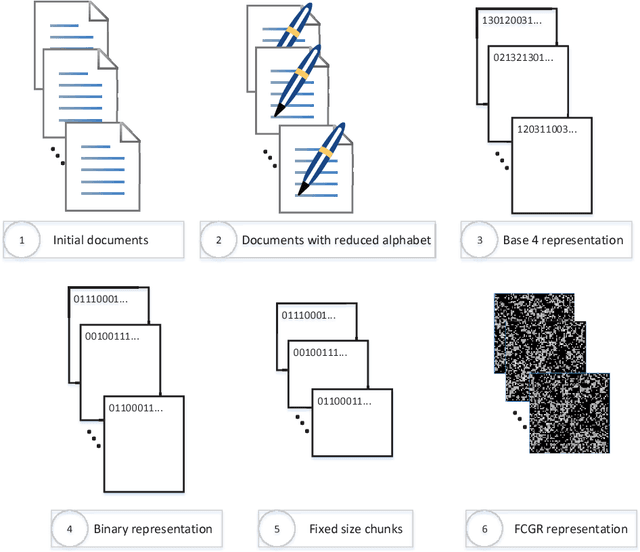
The Chaos Game Representation, a method for creating images from nucleotide sequences, is modified to make images from chunks of text documents. Machine learning methods are then applied to train classifiers based on authorship. Experiments are conducted on several benchmark data sets in English, including the widely used Federalist Papers, and one in Portuguese. Validation results for the trained classifiers are competitive with the best methods in prior literature. The methodology is also successfully applied for text categorization with encouraging results. One classifier method is moreover seen to hold promise for the task of digital fingerprinting.
Via