 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Wikidata's edit history in knowledge graph refinement tasks
Oct 27, 2022Knowledge graphs have been adopted in many diverse fields for a variety of purposes. Most of those applications rely on valid and complete data to deliver their results, pressing the need to improve the quality of knowledge graphs. A number of solutions have been proposed to that end, ranging from rule-based approaches to the use of probabilistic methods, but there is an element that has not been considered yet: the edit history of the graph. In the case of collaborative knowledge graphs (e.g., Wikidata), those edits represent the process in which the community reaches some kind of fuzzy and distributed consensus over the information that best represents each entity, and can hold potentially interesting information to be used by knowledge graph refinement methods. In this paper, we explore the use of edit history information from Wikidata to improve the performance of type prediction methods. To do that, we have first built a JSON dataset containing the edit history of every instance from the 100 most important classes in Wikidata. This edit history information is then explored and analyzed, with a focus on its potential applicability in knowledge graph refinement tasks. Finally, we propose and evaluate two new methods to leverage this edit history information in knowledge graph embedding models for type prediction tasks. Our results show an improvement in one of the proposed methods against current approaches, showing the potential of using edit information in knowledge graph refinement tasks and opening new promising research lines within the field.
Automatic Taxonomy Extraction from Query Logs with no Additional Sources of Information
Oct 05, 2015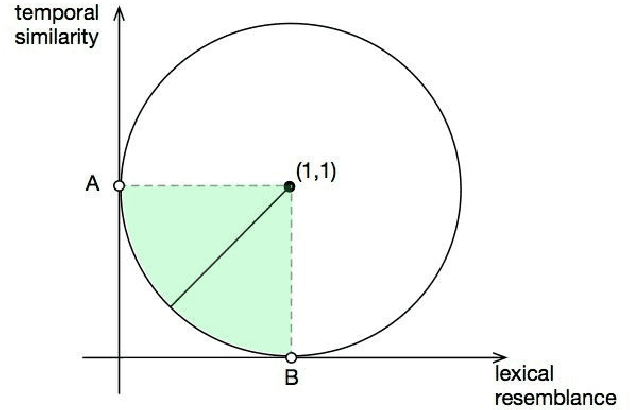
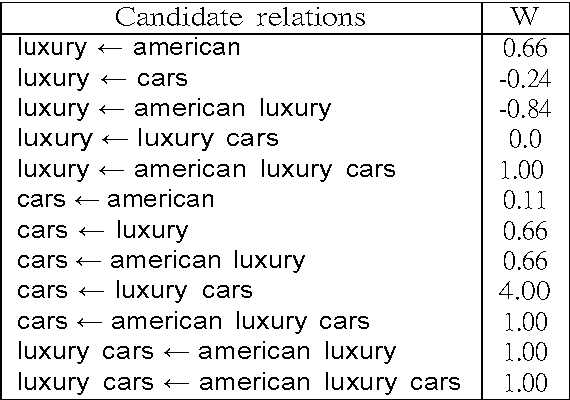
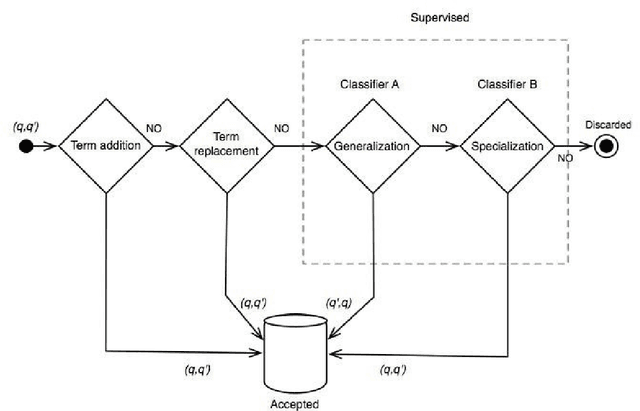
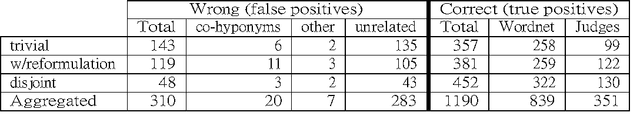
Search engine logs store detailed information on Web users interactions. Thus, as more and more people use search engines on a daily basis, important trails of users common knowledge are being recorded in those files. Previous research has shown that it is possible to extract concept taxonomies from full text documents, while other scholars have proposed methods to obtain similar queries from query logs. We propose a mixture of both lines of research, that is, mining query logs not to find related queries nor query hierarchies, but actual term taxonomies that could be used to improve search engine effectiveness and efficiency. As a result, in this study we have developed a method that combines lexical heuristics with a supervised classification model to successfully extract hyponymy relations from specialization search patterns revealed from log missions, with no additional sources of information, and in a language independent way.
A meta-analysis of state-of-the-art electoral prediction from Twitter data
Jun 25, 2012
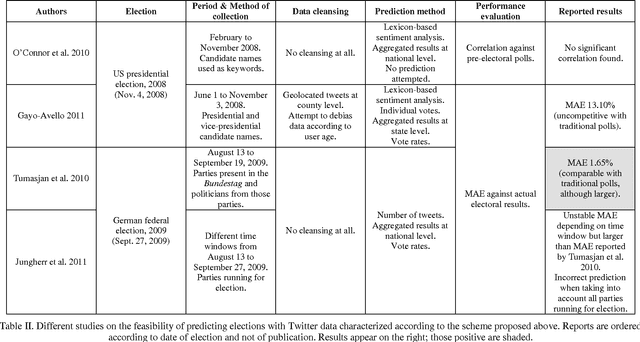

Electoral prediction from Twitter data is an appealing research topic. It seems relatively straightforward and the prevailing view is overly optimistic. This is problematic because while simple approaches are assumed to be good enough, core problems are not addressed. Thus, this paper aims to (1) provide a balanced and critical review of the state of the art; (2) cast light on the presume predictive power of Twitter data; and (3) depict a roadmap to push forward the field. Hence, a scheme to characterize Twitter prediction methods is proposed. It covers every aspect from data collection to performance evaluation, through data processing and vote inference. Using that scheme, prior research is analyzed and organized to explain the main approaches taken up to date but also their weaknesses. This is the first meta-analysis of the whole body of research regarding electoral prediction from Twitter data. It reveals that its presumed predictive power regarding electoral prediction has been rather exaggerated: although social media may provide a glimpse on electoral outcomes current research does not provide strong evidence to support it can replace traditional polls. Finally, future lines of research along with a set of requirements they must fulfill are provided.
* 19 pages, 3 tables
"I Wanted to Predict Elections with Twitter and all I got was this Lousy Paper" -- A Balanced Survey on Election Prediction using Twitter Data
Apr 28, 2012Predicting X from Twitter is a popular fad within the Twitter research subculture. It seems both appealing and relatively easy. Among such kind of studies, electoral prediction is maybe the most attractive, and at this moment there is a growing body of literature on such a topic. This is not only an interesting research problem but, above all, it is extremely difficult. However, most of the authors seem to be more interested in claiming positive results than in providing sound and reproducible methods. It is also especially worrisome that many recent papers seem to only acknowledge those studies supporting the idea of Twitter predicting elections, instead of conducting a balanced literature review showing both sides of the matter. After reading many of such papers I have decided to write such a survey myself. Hence, in this paper, every study relevant to the matter of electoral prediction using social media is commented. From this review it can be concluded that the predictive power of Twitter regarding elections has been greatly exaggerated, and that hard research problems still lie ahead.
Building Chinese Lexicons from Scratch by Unsupervised Short Document Self-Segmentation
Nov 20, 2004Chinese text segmentation is a well-known and difficult problem. On one side, there is not a simple notion of "word" in Chinese language making really hard to implement rule-based systems to segment written texts, thus lexicons and statistical information are usually employed to achieve such a task. On the other side, any piece of Chinese text usually includes segments present neither in the lexicons nor in the training data. Even worse, such unseen sequences can be segmented into a number of totally unrelated words making later processing phases difficult. For instance, using a lexicon-based system the sequence ???(Baluozuo, Barroso, current president-designate of the European Commission) can be segmented into ?(ba, to hope, to wish) and ??(luozuo, an undefined word) changing completely the meaning of the sentence. A new and extremely simple algorithm specially suited to work over short Chinese documents is introduced. This new algorithm performs text "self-segmentation" producing results comparable to those achieved by native speakers without using either lexicons or any statistical information beyond the obtained from the input text. Furthermore, it is really robust for finding new "words", especially proper nouns, and it is well suited to build lexicons from scratch. Some preliminary results are provided in addition to examples of its employment.