 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePixel-wise RL on Diffusion Models: Reinforcement Learning from Rich Feedback
Apr 05, 2024
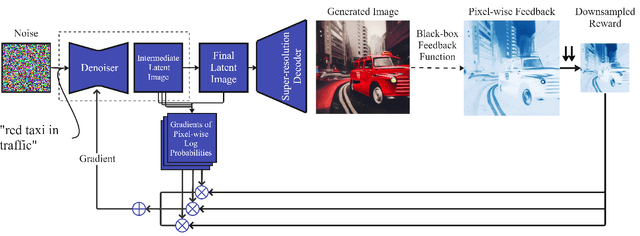

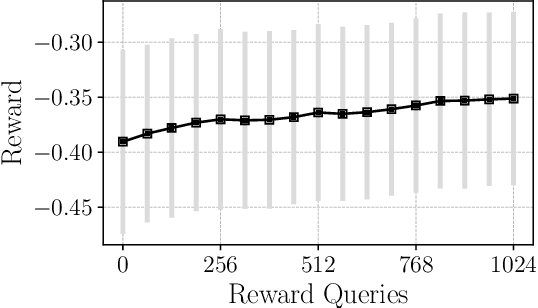
Latent diffusion models are the state-of-the-art for synthetic image generation. To align these models with human preferences, training the models using reinforcement learning on human feedback is crucial. Black et. al 2024 introduced denoising diffusion policy optimisation (DDPO), which accounts for the iterative denoising nature of the generation by modelling it as a Markov chain with a final reward. As the reward is a single value that determines the model's performance on the entire image, the model has to navigate a very sparse reward landscape and so requires a large sample count. In this work, we extend the DDPO by presenting the Pixel-wise Policy Optimisation (PXPO) algorithm, which can take feedback for each pixel, providing a more nuanced reward to the model.