 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Contrastive Learning
Oct 01, 2021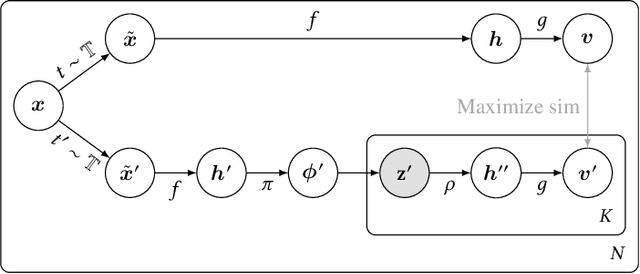


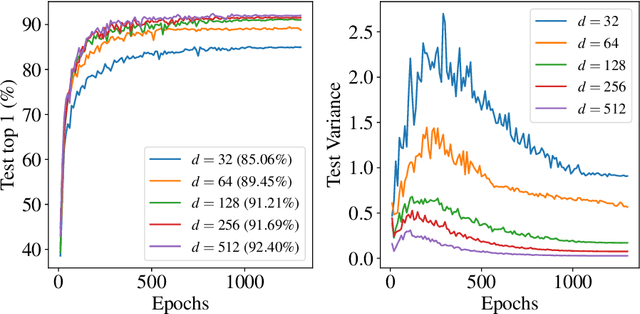
While state-of-the-art contrastive Self-Supervised Learning (SSL) models produce results competitive with their supervised counterparts, they lack the ability to infer latent variables. In contrast, prescribed latent variable (LV) models enable attributing uncertainty, inducing task specific compression, and in general allow for more interpretable representations. In this work, we introduce LV approximations to large scale contrastive SSL models. We demonstrate that this addition improves downstream performance (resulting in 96.42% and 77.49% test top-1 fine-tuned performance on CIFAR10 and ImageNet respectively with a ResNet50) as well as producing highly compressed representations (588x reduction) that are useful for interpretability, classification and regression downstream tasks.