 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling human decomposition: a Bayesian approach
Nov 14, 2024
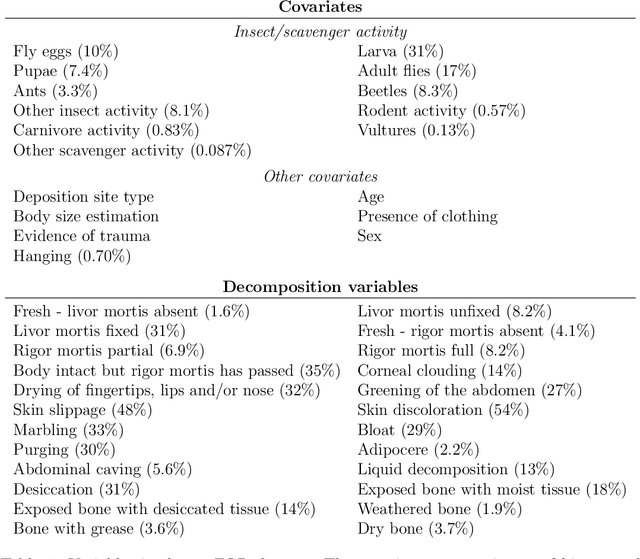
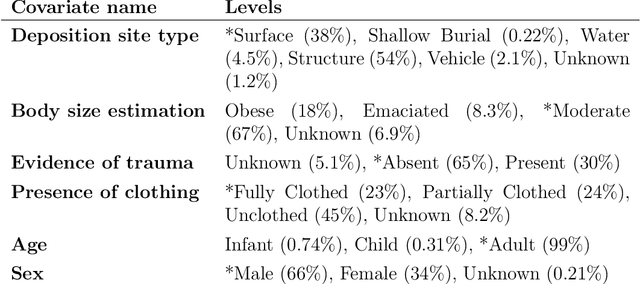
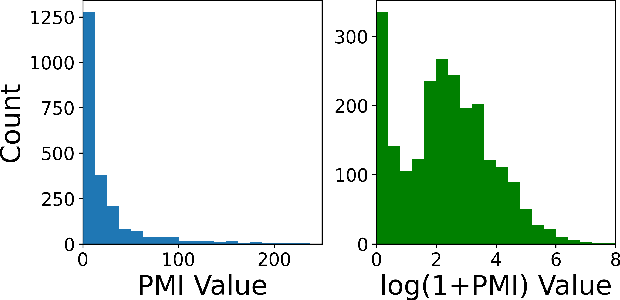
Environmental and individualistic variables affect the rate of human decomposition in complex ways. These effects complicate the estimation of the postmortem interval (PMI) based on observed decomposition characteristics. In this work, we develop a generative probabilistic model for decomposing human remains based on PMI and a wide range of environmental and individualistic variables. This model explicitly represents the effect of each variable, including PMI, on the appearance of each decomposition characteristic, allowing for direct interpretation of model effects and enabling the use of the model for PMI inference and optimal experimental design. In addition, the probabilistic nature of the model allows for the integration of expert knowledge in the form of prior distributions. We fit this model to a diverse set of 2,529 cases from the GeoFOR dataset. We demonstrate that the model accurately predicts 24 decomposition characteristics with an ROC AUC score of 0.85. Using Bayesian inference techniques, we invert the decomposition model to predict PMI as a function of the observed decomposition characteristics and environmental and individualistic variables, producing an R-squared measure of 71%. Finally, we demonstrate how to use the fitted model to design future experiments that maximize the expected amount of new information about the mechanisms of decomposition using the Expected Information Gain formalism.
On the Relevance of Temporal Features for Medical Ultrasound Video Recognition
Oct 16, 2023Many medical ultrasound video recognition tasks involve identifying key anatomical features regardless of when they appear in the video suggesting that modeling such tasks may not benefit from temporal features. Correspondingly, model architectures that exclude temporal features may have better sample efficiency. We propose a novel multi-head attention architecture that incorporates these hypotheses as inductive priors to achieve better sample efficiency on common ultrasound tasks. We compare the performance of our architecture to an efficient 3D CNN video recognition model in two settings: one where we expect not to require temporal features and one where we do. In the former setting, our model outperforms the 3D CNN - especially when we artificially limit the training data. In the latter, the outcome reverses. These results suggest that expressive time-independent models may be more effective than state-of-the-art video recognition models for some common ultrasound tasks in the low-data regime.
* 14 pages, 4 figures, published in MICCAI 23