 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnabling Predictive Maintenance in District Heating Substations: A Labelled Dataset and Fault Detection Evaluation Framework based on Service Data
Nov 14, 2025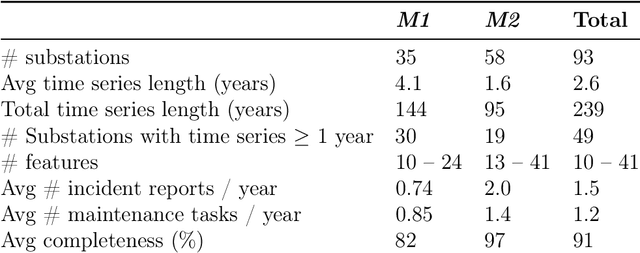
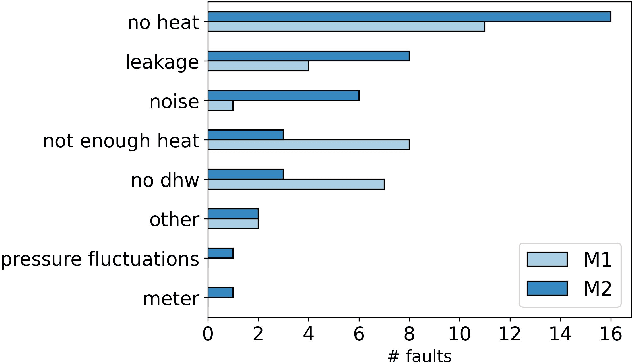
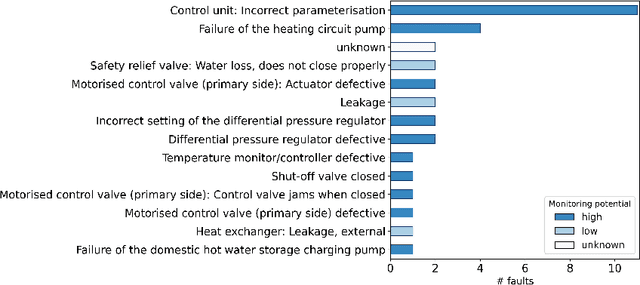

Early detection of faults in district heating substations is imperative to reduce return temperatures and enhance efficiency. However, progress in this domain has been hindered by the limited availability of public, labelled datasets. We present an open source framework combining a service report validated public dataset, an evaluation method based on Accuracy, Reliability, and Earliness, and baseline results implemented with EnergyFaultDetector, an open source Python framework. The dataset contains time series of operational data from 93 substations across two manufacturers, annotated with a list of disturbances due to faults and maintenance actions, a set of normal-event examples and detailed fault metadata. We evaluate the EnergyFaultDetector using three metrics: Accuracy for recognising normal behaviour, an eventwise F Score for reliable fault detection with few false alarms, and Earliness for early detection. The framework also supports root cause analysis using ARCANA. We demonstrate three use cases to assist operators in interpreting anomalies and identifying underlying faults. The models achieve high normal-behaviour accuracy (0.98) and eventwise F-score (beta=0.5) of 0.83, detecting 60% of the faults in the dataset before the customer reports a problem, with an average lead time of 3.9 days. Integrating an open dataset, metrics, open source code, and baselines establishes a reproducible, fault centric benchmark with operationally meaningful evaluation, enabling consistent comparison and development of early fault detection and diagnosis methods for district heating substations.
CARE to Compare: A real-world dataset for anomaly detection in wind turbine data
Apr 18, 2024Anomaly detection plays a crucial role in the field of predictive maintenance for wind turbines, yet the comparison of different algorithms poses a difficult task because domain specific public datasets are scarce. Many comparisons of different approaches either use benchmarks composed of data from many different domains, inaccessible data or one of the few publicly available datasets which lack detailed information about the faults. Moreover, many publications highlight a couple of case studies where fault detection was successful. With this paper we publish a high quality dataset that contains data from 36 wind turbines across 3 different wind farms as well as the most detailed fault information of any public wind turbine dataset as far as we know. The new dataset contains 89 years worth of real-world operating data of wind turbines, distributed across 44 labeled time frames for anomalies that led up to faults, as well as 51 time series representing normal behavior. Additionally, the quality of training data is ensured by turbine-status-based labels for each data point. Furthermore, we propose a new scoring method, called CARE (Coverage, Accuracy, Reliability and Earliness), which takes advantage of the information depth that is present in the dataset to identify a good all-around anomaly detection model. This score considers the anomaly detection performance, the ability to recognize normal behavior properly and the capability to raise as few false alarms as possible while simultaneously detecting anomalies early.
Transfer learning applications for anomaly detection in wind turbines
Apr 03, 2024



Anomaly detection in wind turbines typically involves using normal behaviour models to detect faults early. However, training autoencoder models for each turbine is time-consuming and resource intensive. Thus, transfer learning becomes essential for wind turbines with limited data or applications with limited computational resources. This study examines how cross-turbine transfer learning can be applied to autoencoder-based anomaly detection. Here, autoencoders are combined with constant thresholds for the reconstruction error to determine if input data contains an anomaly. The models are initially trained on one year's worth of data from one or more source wind turbines. They are then fine-tuned using smaller amounts of data from another turbine. Three methods for fine-tuning are investigated: adjusting the entire autoencoder, only the decoder, or only the threshold of the model. The performance of the transfer learning models is compared to baseline models that were trained on one year's worth of data from the target wind turbine. The results of the tests conducted in this study indicate that models trained on data of multiple wind turbines do not improve the anomaly detection capability compared to models trained on data of one source wind turbine. In addition, modifying the model's threshold can lead to comparable or even superior performance compared to the baseline, whereas fine-tuning the decoder or autoencoder further enhances the models' performance.