 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging the Usability Gap: Lessons from Interpreting Studies for Machine Interpreting Design
Jun 16, 2026Machine interpreting (MI), the live, real-time application of speech translation, has achieved remarkable progress on standard benchmarks, with some systems approaching human parity on textual fidelity. Yet the user experience remains far inferior to interpreter-mediated communication, revealing what we term the accuracy illusion: systems that appear accurate on paper but fail in practice to support smooth, goal-oriented interaction. This paper defines MI as a distinct subfield of speech translation, with its own characteristics and the need for evaluation methods grounded in communicative effectiveness rather than isolated fidelity metrics. Drawing on insights from interpreting studies, we identify critical dimensions of professional interpreting practice that are overlooked by current systems, and consolidate them into three interdependent design priorities for future MI: agency (context-sensitive initiative and repair), grounding (multimodal and discourse-level situational awareness), and experience (adaptive improvement through real interaction). Together, these priorities chart a path toward closing the usability gap and enabling systems that can sustain authentic multilingual communication in real time.
Exploring the Correlation between Human and Machine Evaluation of Simultaneous Speech Translation
Jun 14, 2024



Assessing the performance of interpreting services is a complex task, given the nuanced nature of spoken language translation, the strategies that interpreters apply, and the diverse expectations of users. The complexity of this task become even more pronounced when automated evaluation methods are applied. This is particularly true because interpreted texts exhibit less linearity between the source and target languages due to the strategies employed by the interpreter. This study aims to assess the reliability of automatic metrics in evaluating simultaneous interpretations by analyzing their correlation with human evaluations. We focus on a particular feature of interpretation quality, namely translation accuracy or faithfulness. As a benchmark we use human assessments performed by language experts, and evaluate how well sentence embeddings and Large Language Models correlate with them. We quantify semantic similarity between the source and translated texts without relying on a reference translation. The results suggest GPT models, particularly GPT-3.5 with direct prompting, demonstrate the strongest correlation with human judgment in terms of semantic similarity between source and target texts, even when evaluating short textual segments. Additionally, the study reveals that the size of the context window has a notable impact on this correlation.
Defining maximum acceptable latency of AI-enhanced CAI tools
Jan 08, 2022
Recent years have seen an increasing number of studies around the design of computer-assisted interpreting tools with integrated automatic speech processing and their use by trainees and professional interpreters. This paper discusses the role of system latency of such tools and presents the results of an experiment designed to investigate the maximum system latency that is cognitively acceptable for interpreters working in the simultaneous modality. The results show that interpreters can cope with a system latency of 3 seconds without any major impact in the rendition of the original text, both in terms of accuracy and fluency. This value is above the typical latency of available AI-based CAI tools and paves the way to experiment with larger context-based language models and higher latencies.
KUDO Interpreter Assist: Automated Real-time Support for Remote Interpretation
Jan 05, 2022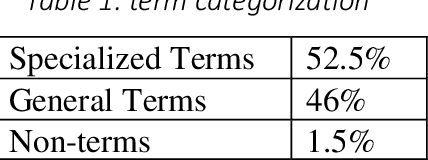
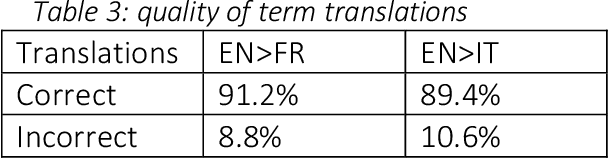
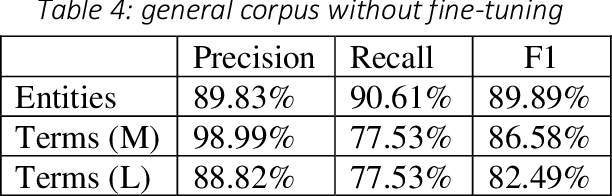
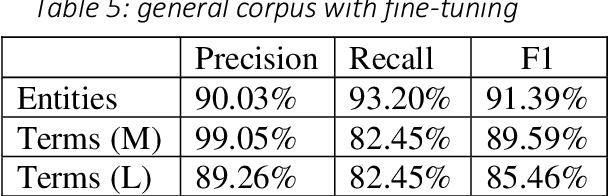
High-quality human interpretation requires linguistic and factual preparation as well as the ability to retrieve information in real-time. This situation becomes particularly relevant in the context of remote simultaneous interpreting (RSI) where time-to-event may be short, posing new challenges to professional interpreters and their commitment to delivering high-quality services. In order to mitigate these challenges, we present Interpreter Assist, a computer-assisted interpreting tool specifically designed for the integration in RSI scenarios. Interpreter Assist comprises two main feature sets: an automatic glossary creation tool and a real-time suggestion system. In this paper, we describe the overall design of our tool, its integration into the typical RSI workflow, and the results achieved on benchmark tests both in terms of quality and relevance of glossary creation as well as in precision and recall of the real-time suggestion feature.