 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKLIF: An optimized spiking neuron unit for tuning surrogate gradient slope and membrane potential
Feb 18, 2023



Spiking neural networks (SNNs) have attracted much attention due to their ability to process temporal information, low power consumption, and higher biological plausibility. However, it is still challenging to develop efficient and high-performing learning algorithms for SNNs. Methods like artificial neural network (ANN)-to-SNN conversion can transform ANNs to SNNs with slight performance loss, but it needs a long simulation to approximate the rate coding. Directly training SNN by spike-based backpropagation (BP) such as surrogate gradient approximation is more flexible. Yet now, the performance of SNNs is not competitive compared with ANNs. In this paper, we propose a novel k-based leaky Integrate-and-Fire (KLIF) neuron model to improve the learning ability of SNNs. Compared with the popular leaky integrate-and-fire (LIF) model, KLIF adds a learnable scaling factor to dynamically update the slope and width of the surrogate gradient curve during training and incorporates a ReLU activation function that selectively delivers membrane potential to spike firing and resetting. The proposed spiking unit is evaluated on both static MNIST, Fashion-MNIST, CIFAR-10 datasets, as well as neuromorphic N-MNIST, CIFAR10-DVS, and DVS128-Gesture datasets. Experiments indicate that KLIF performs much better than LIF without introducing additional computational cost and achieves state-of-the-art performance on these datasets with few time steps. Also, KLIF is believed to be more biological plausible than LIF. The good performance of KLIF can make it completely replace the role of LIF in SNN for various tasks.
A noise based novel strategy for faster SNN training
Nov 10, 2022Spiking neural networks (SNNs) are receiving increasing attention due to their low power consumption and strong bio-plausibility. Optimization of SNNs is a challenging task. Two main methods, artificial neural network (ANN)-to-SNN conversion and spike-based backpropagation (BP), both have their advantages and limitations. For ANN-to-SNN conversion, it requires a long inference time to approximate the accuracy of ANN, thus diminishing the benefits of SNN. With spike-based BP, training high-precision SNNs typically consumes dozens of times more computational resources and time than their ANN counterparts. In this paper, we propose a novel SNN training approach that combines the benefits of the two methods. We first train a single-step SNN by approximating the neural potential distribution with random noise, then convert the single-step SNN to a multi-step SNN losslessly. The introduction of Gaussian distributed noise leads to a significant gain in accuracy after conversion. The results show that our method considerably reduces the training and inference times of SNNs while maintaining their high accuracy. Compared to the previous two methods, ours can reduce training time by 65%-75% and achieves more than 100 times faster inference speed. We also argue that the neuron model augmented with noise makes it more bio-plausible.
Spiking sampling network for image sparse representation and dynamic vision sensor data compression
Nov 08, 2022
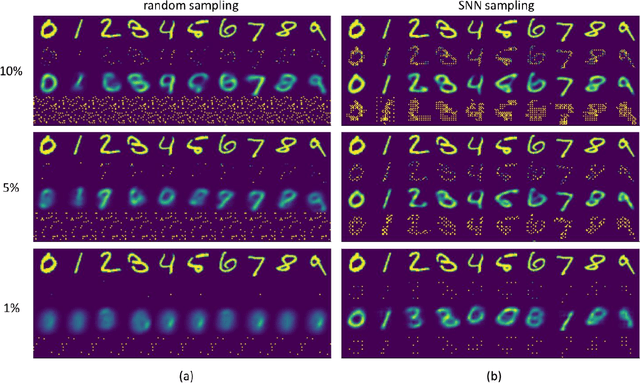
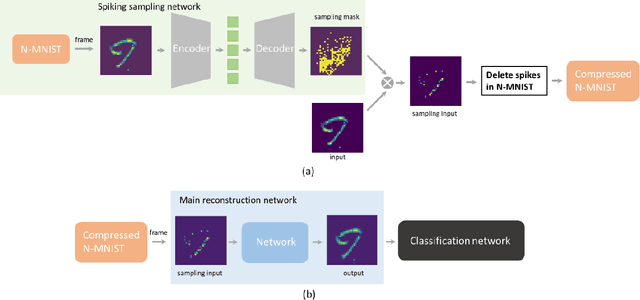
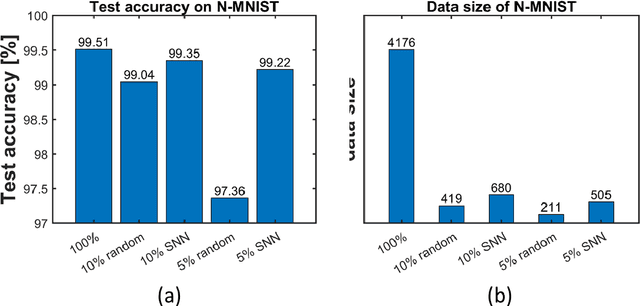
Sparse representation has attracted great attention because it can greatly save storage resources and find representative features of data in a low-dimensional space. As a result, it may be widely applied in engineering domains including feature extraction, compressed sensing, signal denoising, picture clustering, and dictionary learning, just to name a few. In this paper, we propose a spiking sampling network. This network is composed of spiking neurons, and it can dynamically decide which pixel points should be retained and which ones need to be masked according to the input. Our experiments demonstrate that this approach enables better sparse representation of the original image and facilitates image reconstruction compared to random sampling. We thus use this approach for compressing massive data from the dynamic vision sensor, which greatly reduces the storage requirements for event data.
Adversarial Defense via Neural Oscillation inspired Gradient Masking
Nov 04, 2022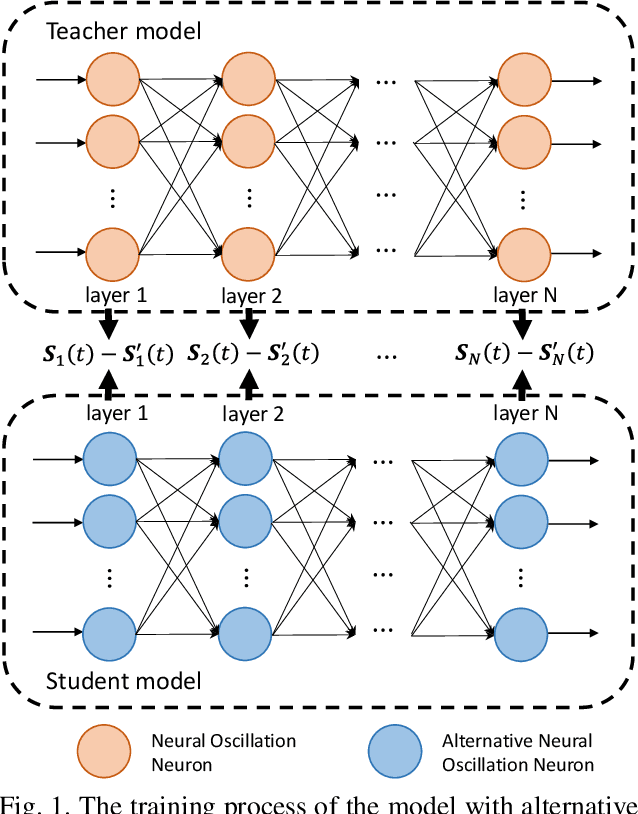


Spiking neural networks (SNNs) attract great attention due to their low power consumption, low latency, and biological plausibility. As they are widely deployed in neuromorphic devices for low-power brain-inspired computing, security issues become increasingly important. However, compared to deep neural networks (DNNs), SNNs currently lack specifically designed defense methods against adversarial attacks. Inspired by neural membrane potential oscillation, we propose a novel neural model that incorporates the bio-inspired oscillation mechanism to enhance the security of SNNs. Our experiments show that SNNs with neural oscillation neurons have better resistance to adversarial attacks than ordinary SNNs with LIF neurons on kinds of architectures and datasets. Furthermore, we propose a defense method that changes model's gradients by replacing the form of oscillation, which hides the original training gradients and confuses the attacker into using gradients of 'fake' neurons to generate invalid adversarial samples. Our experiments suggest that the proposed defense method can effectively resist both single-step and iterative attacks with comparable defense effectiveness and much less computational costs than adversarial training methods on DNNs. To the best of our knowledge, this is the first work that establishes adversarial defense through masking surrogate gradients on SNNs.