 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-1-to-A: Zero-Shot One Image to Animatable Head Avatars Using Video Diffusion
Mar 20, 2025Animatable head avatar generation typically requires extensive data for training. To reduce the data requirements, a natural solution is to leverage existing data-free static avatar generation methods, such as pre-trained diffusion models with score distillation sampling (SDS), which align avatars with pseudo ground-truth outputs from the diffusion model. However, directly distilling 4D avatars from video diffusion often leads to over-smooth results due to spatial and temporal inconsistencies in the generated video. To address this issue, we propose Zero-1-to-A, a robust method that synthesizes a spatial and temporal consistency dataset for 4D avatar reconstruction using the video diffusion model. Specifically, Zero-1-to-A iteratively constructs video datasets and optimizes animatable avatars in a progressive manner, ensuring that avatar quality increases smoothly and consistently throughout the learning process. This progressive learning involves two stages: (1) Spatial Consistency Learning fixes expressions and learns from front-to-side views, and (2) Temporal Consistency Learning fixes views and learns from relaxed to exaggerated expressions, generating 4D avatars in a simple-to-complex manner. Extensive experiments demonstrate that Zero-1-to-A improves fidelity, animation quality, and rendering speed compared to existing diffusion-based methods, providing a solution for lifelike avatar creation. Code is publicly available at: https://github.com/ZhenglinZhou/Zero-1-to-A.
GRCN: Graph-Refined Convolutional Network for Multimedia Recommendation with Implicit Feedback
Nov 03, 2021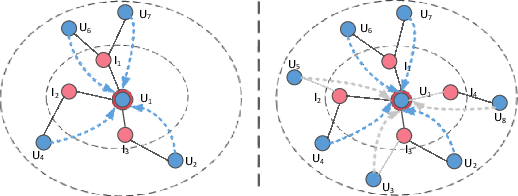
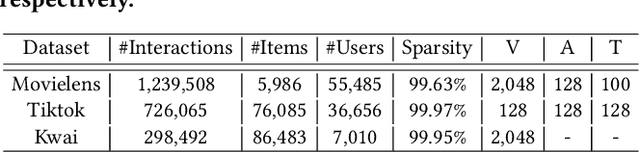
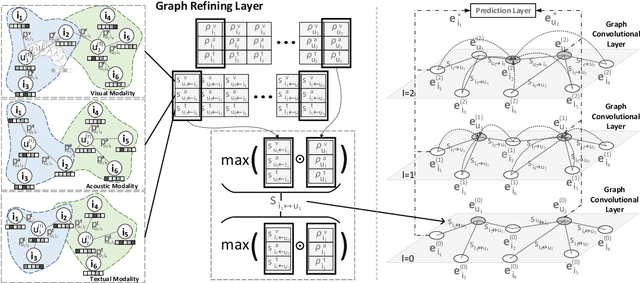
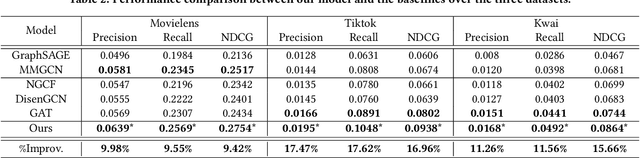
Reorganizing implicit feedback of users as a user-item interaction graph facilitates the applications of graph convolutional networks (GCNs) in recommendation tasks. In the interaction graph, edges between user and item nodes function as the main element of GCNs to perform information propagation and generate informative representations. Nevertheless, an underlying challenge lies in the quality of interaction graph, since observed interactions with less-interested items occur in implicit feedback (say, a user views micro-videos accidentally). This means that the neighborhoods involved with such false-positive edges will be influenced negatively and the signal on user preference can be severely contaminated. However, existing GCN-based recommender models leave such challenge under-explored, resulting in suboptimal representations and performance. In this work, we focus on adaptively refining the structure of interaction graph to discover and prune potential false-positive edges. Towards this end, we devise a new GCN-based recommender model, \emph{Graph-Refined Convolutional Network} (GRCN), which adjusts the structure of interaction graph adaptively based on status of model training, instead of remaining the fixed structure. In particular, a graph refining layer is designed to identify the noisy edges with the high confidence of being false-positive interactions, and consequently prune them in a soft manner. We then apply a graph convolutional layer on the refined graph to distill informative signals on user preference. Through extensive experiments on three datasets for micro-video recommendation, we validate the rationality and effectiveness of our GRCN. Further in-depth analysis presents how the refined graph benefits the GCN-based recommender model.
Hierarchical User Intent Graph Network forMultimedia Recommendation
Oct 28, 2021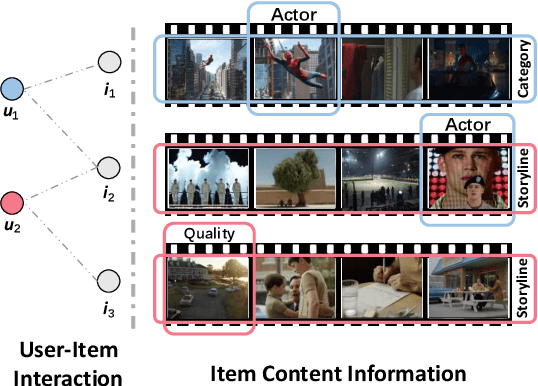
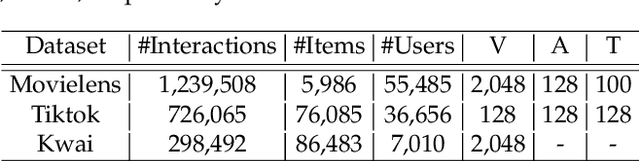
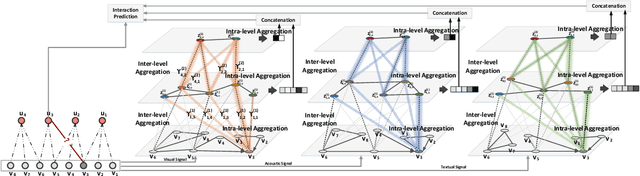
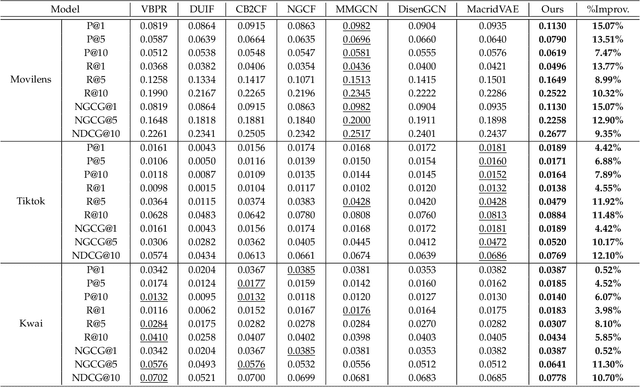
In this work, we aim to learn multi-level user intents from the co-interacted patterns of items, so as to obtain high-quality representations of users and items and further enhance the recommendation performance. Towards this end, we develop a novel framework, Hierarchical User Intent Graph Network, which exhibits user intents in a hierarchical graph structure, from the fine-grained to coarse-grained intents. In particular, we get the multi-level user intents by recursively performing two operations: 1) intra-level aggregation, which distills the signal pertinent to user intents from co-interacted item graphs; and 2) inter-level aggregation, which constitutes the supernode in higher levels to model coarser-grained user intents via gathering the nodes' representations in the lower ones. Then, we refine the user and item representations as a distribution over the discovered intents, instead of simple pre-existing features. To demonstrate the effectiveness of our model, we conducted extensive experiments on three public datasets. Our model achieves significant improvements over the state-of-the-art methods, including MMGCN and DisenGCN. Furthermore, by visualizing the item representations, we provide the semantics of user intents.