 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLineup Regularized Adjusted Plus-Minus (L-RAPM): Basketball Lineup Ratings with Informed Priors
Jan 21, 2026Identifying combinations of players (that is, lineups) in basketball - and other sports - that perform well when they play together is one of the most important tasks in sports analytics. One of the main challenges associated with this task is the frequent substitutions that occur during a game, which results in highly sparse data. In particular, a National Basketball Association (NBA) team will use more than 600 lineups during a season, which translates to an average lineup having seen the court in approximately 25-30 possessions. Inevitably, any statistics that one collects for these lineups are going to be noisy, with low predictive value. Yet, there is no existing work (in the public at least) that addresses this problem. In this work, we propose a regression-based approach that controls for the opposition faced by each lineup, while it also utilizes information about the players making up the lineups. Our experiments show that L-RAPM provides improved predictive power than the currently used baseline, and this improvement increases as the sample size for the lineups gets smaller.
Text Classification: Neural Networks VS Machine Learning Models VS Pre-trained Models
Dec 30, 2024
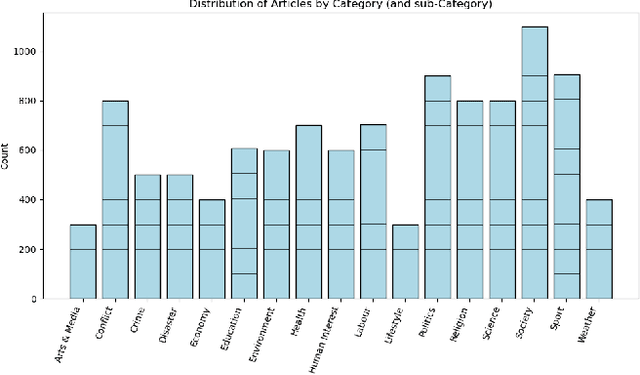
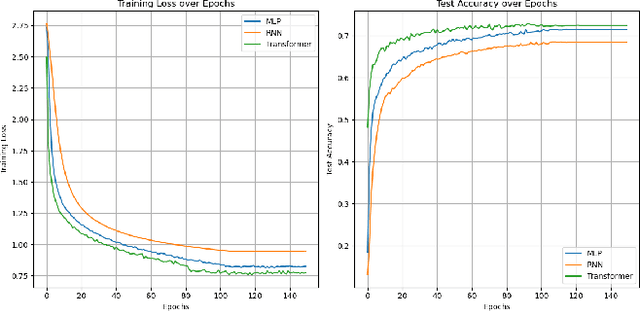
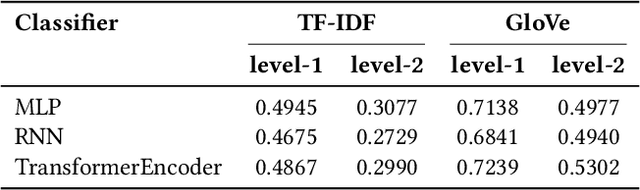
Text classification is a very common task nowadays and there are many efficient methods and algorithms that we can employ to accomplish it. Transformers have revolutionized the field of deep learning, particularly in Natural Language Processing (NLP) and have rapidly expanded to other domains such as computer vision, time-series analysis and more. The transformer model was firstly introduced in the context of machine translation and its architecture relies on self-attention mechanisms to capture complex relationships within data sequences. It is able to handle long-range dependencies more effectively than traditional neural networks (such as Recurrent Neural Networks and Multilayer Perceptrons). In this work, we present a comparison between different techniques to perform text classification. We take into consideration seven pre-trained models, three standard neural networks and three machine learning models. For standard neural networks and machine learning models we also compare two embedding techniques: TF-IDF and GloVe, with the latter consistently outperforming the former. Finally, we demonstrate the results from our experiments where pre-trained models such as BERT and DistilBERT always perform better than standard models/algorithms.