 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative diffusion models for agricultural AI: plant image generation, indoor-to-outdoor translation, and expert preference alignment
Dec 22, 2025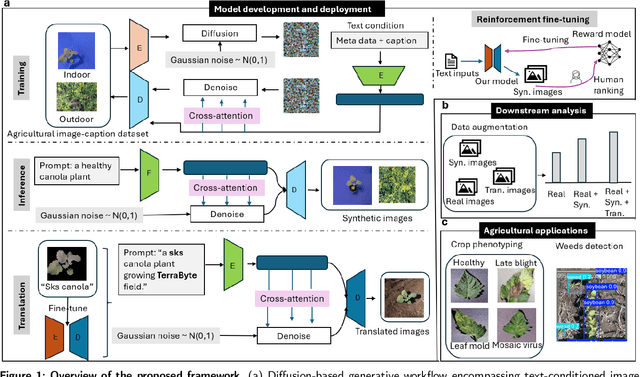
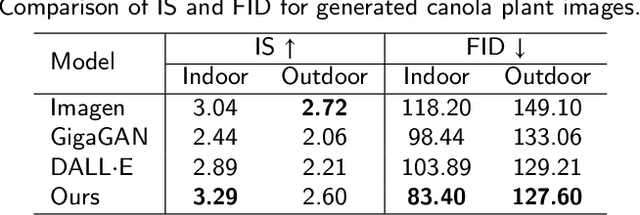
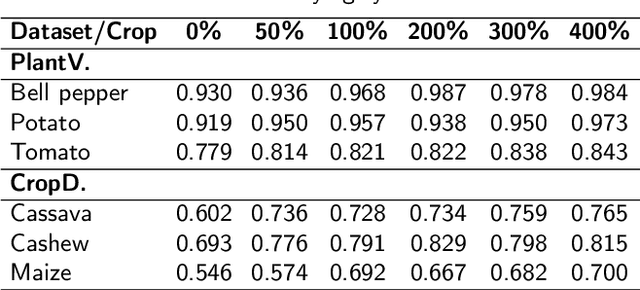
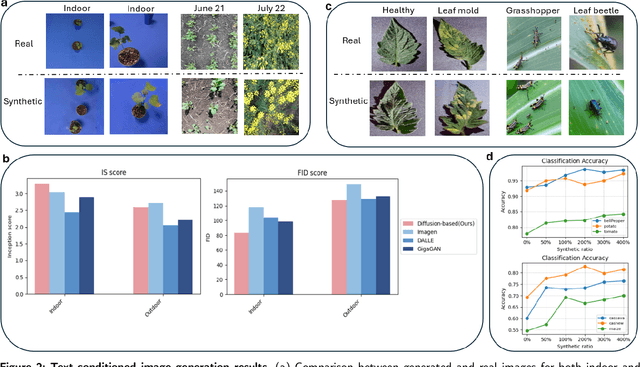
The success of agricultural artificial intelligence depends heavily on large, diverse, and high-quality plant image datasets, yet collecting such data in real field conditions is costly, labor intensive, and seasonally constrained. This paper investigates diffusion-based generative modeling to address these challenges through plant image synthesis, indoor-to-outdoor translation, and expert preference aligned fine tuning. First, a Stable Diffusion model is fine tuned on captioned indoor and outdoor plant imagery to generate realistic, text conditioned images of canola and soybean. Evaluation using Inception Score, Frechet Inception Distance, and downstream phenotype classification shows that synthetic images effectively augment training data and improve accuracy. Second, we bridge the gap between high resolution indoor datasets and limited outdoor imagery using DreamBooth-based text inversion and image guided diffusion, generating translated images that enhance weed detection and classification with YOLOv8. Finally, a preference guided fine tuning framework trains a reward model on expert scores and applies reward weighted updates to produce more stable and expert aligned outputs. Together, these components demonstrate a practical pathway toward data efficient generative pipelines for agricultural AI.
A Low-Cost Photogrammetry System for 3D Plant Modeling and Phenotyping
Apr 23, 2025We present an open-source, low-cost photogrammetry system for 3D plant modeling and phenotyping. The system uses a structure-from-motion approach to reconstruct 3D representations of the plants via point clouds. Using wheat as an example, we demonstrate how various phenotypic traits can be computed easily from the point clouds. These include standard measurements such as plant height and radius, as well as features that would be more cumbersome to measure by hand, such as leaf angles and convex hull. We further demonstrate the utility of the system through the investigation of specific metrics that may yield objective classifications of erectophile versus planophile wheat canopy architectures.
Strategies and impact of learning curve estimation for CNN-based image classification
Oct 12, 2023



Learning curves are a measure for how the performance of machine learning models improves given a certain volume of training data. Over a wide variety of applications and models it was observed that learning curves follow -- to a large extent -- a power law behavior. This makes the performance of different models for a given task somewhat predictable and opens the opportunity to reduce the training time for practitioners, who are exploring the space of possible models and hyperparameters for the problem at hand. By estimating the learning curve of a model from training on small subsets of data only the best models need to be considered for training on the full dataset. How to choose subset sizes and how often to sample models on these to obtain estimates is however not researched. Given that the goal is to reduce overall training time strategies are needed that sample the performance in a time-efficient way and yet leads to accurate learning curve estimates. In this paper we formulate the framework for these strategies and propose several strategies. Further we evaluate the strategies for simulated learning curves and in experiments with popular datasets and models for image classification tasks.
A comprehensive review of 3D convolutional neural network-based classification techniques of diseased and defective crops using non-UAV-based hyperspectral images
Jun 15, 2023Hyperspectral imaging (HSI) is a non-destructive and contactless technology that provides valuable information about the structure and composition of an object. It can capture detailed information about the chemical and physical properties of agricultural crops. Due to its wide spectral range, compared with multispectral- or RGB-based imaging methods, HSI can be a more effective tool for monitoring crop health and productivity. With the advent of this imaging tool in agrotechnology, researchers can more accurately address issues related to the detection of diseased and defective crops in the agriculture industry. This allows to implement the most suitable and accurate farming solutions, such as irrigation and fertilization before crops enter a damaged and difficult-to-recover phase of growth in the field. While HSI provides valuable insights into the object under investigation, the limited number of HSI datasets for crop evaluation presently poses a bottleneck. Dealing with the curse of dimensionality presents another challenge due to the abundance of spectral and spatial information in each hyperspectral cube. State-of-the-art methods based on 1D- and 2D-CNNs struggle to efficiently extract spectral and spatial information. On the other hand, 3D-CNN-based models have shown significant promise in achieving better classification and detection results by leveraging spectral and spatial features simultaneously. Despite the apparent benefits of 3D-CNN-based models, their usage for classification purposes in this area of research has remained limited. This paper seeks to address this gap by reviewing 3D-CNN-based architectures and the typical deep learning pipeline, including preprocessing and visualization of results, for the classification of hyperspectral images of diseased and defective crops. Furthermore, we discuss open research areas and challenges when utilizing 3D-CNNs with HSI data.
Fusarium head blight detection, spikelet estimation, and severity assessment in wheat using 3D convolutional neural networks
Mar 10, 2023Fusarium head blight (FHB) is one of the most significant diseases affecting wheat and other small grain cereals worldwide. The development of resistant varieties requires the laborious task of field and greenhouse phenotyping. The applications considered in this work are the automated detection of FHB disease symptoms expressed on a wheat plant, the automated estimation of the total number of spikelets and the total number of infected spikelets on a wheat head, and the automated assessment of the FHB severity in infected wheat. The data used to generate the results are 3-dimensional (3D) multispectral point clouds (PC), which are 3D collections of points - each associated with a red, green, blue (RGB), and near-infrared (NIR) measurement. Over 300 wheat plant images were collected using a multispectral 3D scanner, and the labelled UW-MRDC 3D wheat dataset was created. The data was used to develop novel and efficient 3D convolutional neural network (CNN) models for FHB detection, which achieved 100% accuracy. The influence of the multispectral information on performance was evaluated, and our results showed the dominance of the RGB channels over both the NIR and the NIR plus RGB channels combined. Furthermore, novel and efficient 3D CNNs were created to estimate the total number of spikelets and the total number of infected spikelets on a wheat head, and our best models achieved mean absolute errors (MAE) of 1.13 and 1.56, respectively. Moreover, 3D CNN models for FHB severity estimation were created, and our best model achieved 8.6 MAE. A linear regression analysis between the visual FHB severity assessment and the FHB severity predicted by our 3D CNN was performed, and the results showed a significant correlation between the two variables with a 0.0001 P-value and 0.94 R-squared.
Investigating classification learning curves for automatically generated and labelled plant images
May 26, 2022

In the context of supervised machine learning a learning curve describes how a model's performance on unseen data relates to the amount of samples used to train the model. In this paper we present a dataset of plant images with representatives of crops and weeds common to the Manitoba prairies at different growth stages. We determine the learning curve for a classification task on this data with the ResNet architecture. Our results are in accordance with previous studies and add to the evidence that learning curves are governed by power-law relationships over large scales, applications, and models. We further investigate how label noise and the reduction of trainable parameters impacts the learning curve on this dataset. Both effects lead to the model requiring disproportionally larger training sets to achieve the same classification performance as observed without these effects.
The TerraByte Client: providing access to terabytes of plant data
Mar 25, 2022



In this paper we demonstrate the TerraByte Client, a software to download user-defined plant datasets from a data portal hosted at Compute Canada. To that end the client offers two key functionalities: (1) It allows the user to get an overview on what data is available and a quick way to visually check samples of that data. For this the client receives the results of queries to a database and displays the number of images that fulfill the search criteria. Furthermore, a sample can be downloaded within seconds to confirm that the data suits the user's needs. (2) The user can then download the specified data to their own drive. This data is prepared into chunks server-side and sent to the user's end-system, where it is automatically extracted into individual files. The first chunks of data are available for inspection after a brief waiting period of a minute or less depending on available bandwidth and type of data. The TerraByte Client has a full graphical user interface for easy usage and uses end-to-end encryption. The user interface is built on top of a low-level client. This architecture in combination of offering the client program open-source makes it possible for the user to develop their own user interface or use the client's functionality directly. An example for direct usage could be to download specific data on demand within a larger application, such as training machine learning models.
Presenting an extensive lab- and field-image dataset of crops and weeds for computer vision tasks in agriculture
Aug 12, 2021



We present two large datasets of labelled plant-images that are suited towards the training of machine learning and computer vision models. The first dataset encompasses as the day of writing over 1.2 million images of indoor-grown crops and weeds common to the Canadian Prairies and many US states. The second dataset consists of over 540,000 images of plants imaged in farmland. All indoor plant images are labelled by species and we provide rich etadata on the level of individual images. This comprehensive database allows to filter the datasets under user-defined specifications such as for example the crop-type or the age of the plant. Furthermore, the indoor dataset contains images of plants taken from a wide variety of angles, including profile shots, top-down shots, and angled perspectives. The images taken from plants in fields are all from a top-down perspective and contain usually multiple plants per image. For these images metadata is also available. In this paper we describe both datasets' characteristics with respect to plant variety, plant age, and number of images. We further introduce an open-access sample of the indoor-dataset that contains 1,000 images of each species covered in our dataset. These, in total 14,000 images, had been selected, such that they form a representative sample with respect to plant age and ndividual plants per species. This sample serves as a quick entry point for new users to the dataset, allowing them to explore the data on a small scale and find the parameters of data most useful for their application without having to deal with hundreds of thousands of individual images.
An embedded system for the automated generation of labeled plant images to enable machine learning applications in agriculture
Jun 01, 2020



A lack of sufficient training data, both in terms of variety and quantity, is often the bottleneck in the development of machine learning (ML) applications in any domain. For agricultural applications, ML-based models designed to perform tasks such as autonomous plant classification will typically be coupled to just one or perhaps a few plant species. As a consequence, each crop-specific task is very likely to require its own specialized training data, and the question of how to serve this need for data now often overshadows the more routine exercise of actually training such models. To tackle this problem, we have developed an embedded robotic system to automatically generate and label large datasets of plant images for ML applications in agriculture. The system can image plants from virtually any angle, thereby ensuring a wide variety of data; and with an imaging rate of up to one image per second, it can produce lableled datasets on the scale of thousands to tens of thousands of images per day. As such, this system offers an important alternative to time- and cost-intensive methods of manual generation and labeling. Furthermore, the use of a uniform background made of blue keying fabric enables additional image processing techniques such as background replacement and plant segmentation. It also helps in the training process, essentially forcing the model to focus on the plant features and eliminating random correlations. To demonstrate the capabilities of our system, we generated a dataset of over 34,000 labeled images, with which we trained an ML-model to distinguish grasses from non-grasses in test data from a variety of sources. We now plan to generate much larger datasets of Canadian crop plants and weeds that will be made publicly available in the hope of further enabling ML applications in the agriculture sector.