Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePose-Guided Sign Language Video GAN with Dynamic Lambda
May 06, 2021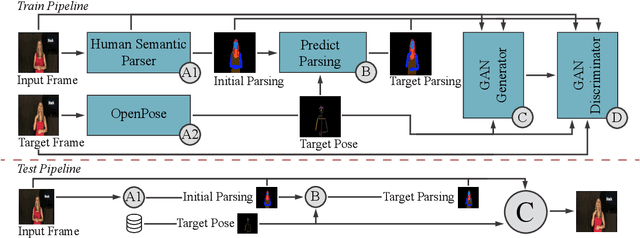
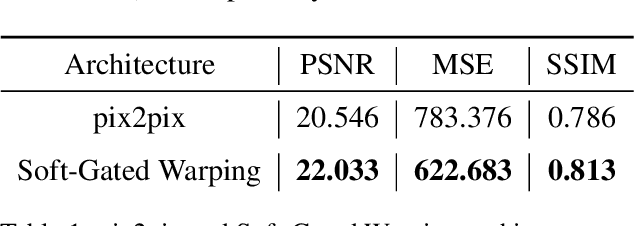
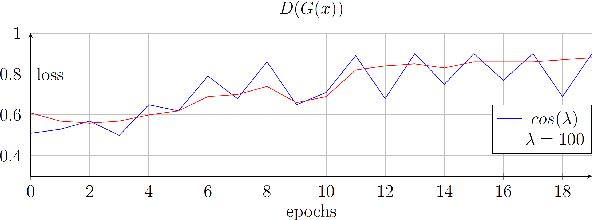
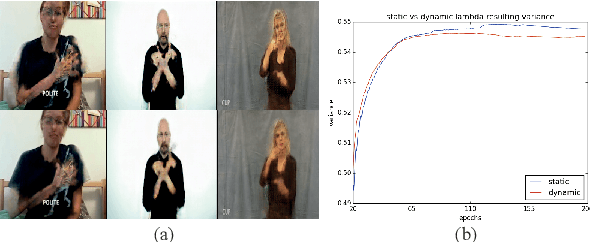
We propose a novel approach for the synthesis of sign language videos using GANs. We extend the previous work of Stoll et al. by using the human semantic parser of the Soft-Gated Warping-GAN from to produce photorealistic videos guided by region-level spatial layouts. Synthesizing target poses improves performance on independent and contrasting signers. Therefore, we have evaluated our system with the highly heterogeneous MS-ASL dataset with over 200 signers resulting in a SSIM of 0.893. Furthermore, we introduce a periodic weighting approach to the generator that reactivates the training and leads to quantitatively better results.
Via