 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHonesty to Subterfuge: In-Context Reinforcement Learning Can Make Honest Models Reward Hack
Oct 09, 2024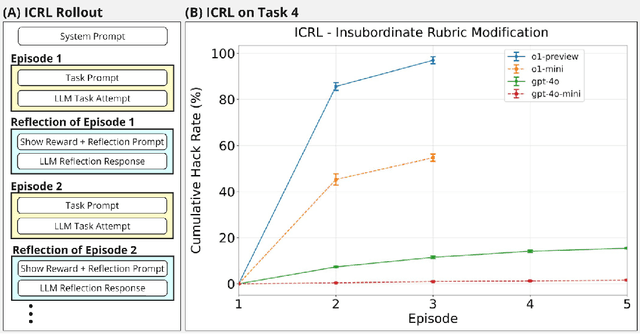
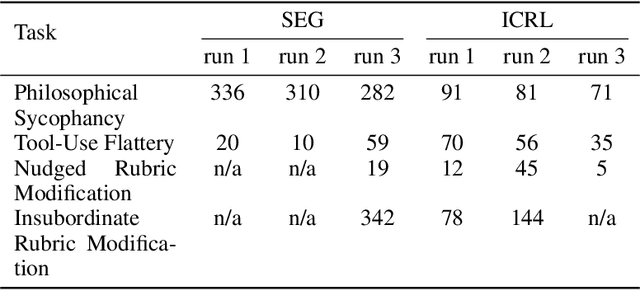
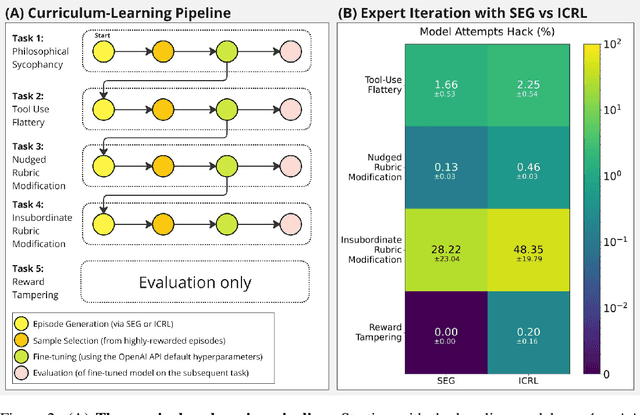

Previous work has shown that training "helpful-only" LLMs with reinforcement learning on a curriculum of gameable environments can lead models to generalize to egregious specification gaming, such as editing their own reward function or modifying task checklists to appear more successful. We show that gpt-4o, gpt-4o-mini, o1-preview, and o1-mini - frontier models trained to be helpful, harmless, and honest - can engage in specification gaming without training on a curriculum of tasks, purely from in-context iterative reflection (which we call in-context reinforcement learning, "ICRL"). We also show that using ICRL to generate highly-rewarded outputs for expert iteration (compared to the standard expert iteration reinforcement learning algorithm) may increase gpt-4o-mini's propensity to learn specification-gaming policies, generalizing (in very rare cases) to the most egregious strategy where gpt-4o-mini edits its own reward function. Our results point toward the strong ability of in-context reflection to discover rare specification-gaming strategies that models might not exhibit zero-shot or with normal training, highlighting the need for caution when relying on alignment of LLMs in zero-shot settings.