 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecision Making for Hierarchical Multi-label Classification with Multidimensional Local Precision Rate
May 16, 2022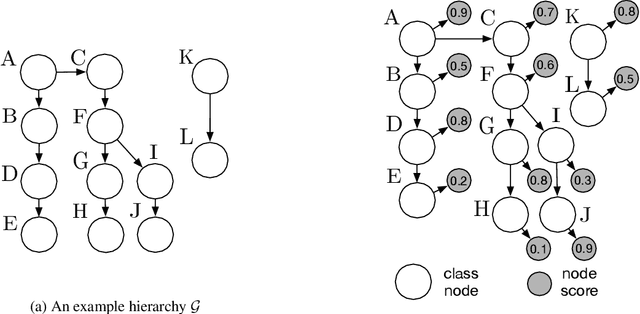


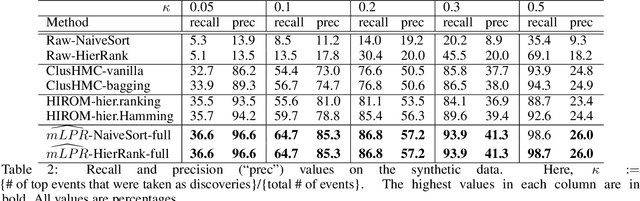
Hierarchical multi-label classification (HMC) has drawn increasing attention in the past few decades. It is applicable when hierarchical relationships among classes are available and need to be incorporated along with the multi-label classification whereby each object is assigned to one or more classes. There are two key challenges in HMC: i) optimizing the classification accuracy, and meanwhile ii) ensuring the given class hierarchy. To address these challenges, in this article, we introduce a new statistic called the multidimensional local precision rate (mLPR) for each object in each class. We show that classification decisions made by simply sorting objects across classes in descending order of their true mLPRs can, in theory, ensure the class hierarchy and lead to the maximization of CATCH, an objective function we introduce that is related to the area under a hit curve. This approach is the first of its kind that handles both challenges in one objective function without additional constraints, thanks to the desirable statistical properties of CATCH and mLPR. In practice, however, true mLPRs are not available. In response, we introduce HierRank, a new algorithm that maximizes an empirical version of CATCH using estimated mLPRs while respecting the hierarchy. The performance of this approach was evaluated on a synthetic data set and two real data sets; ours was found to be superior to several comparison methods on evaluation criteria based on metrics such as precision, recall, and $F_1$ score.
HierLPR: Decision making in hierarchical multi-label classification with local precision rates
Oct 18, 2018


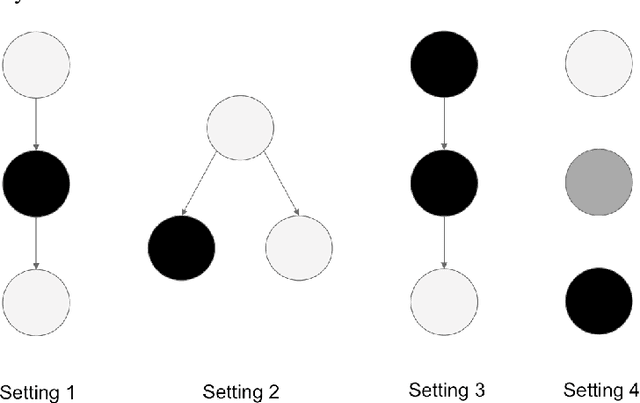
In this article we propose a novel ranking algorithm, referred to as HierLPR, for the multi-label classification problem when the candidate labels follow a known hierarchical structure. HierLPR is motivated by a new metric called eAUC that we design to assess the ranking of classification decisions. This metric, associated with the hit curve and local precision rate, emphasizes the accuracy of the first calls. We show that HierLPR optimizes eAUC under the tree constraint and some light assumptions on the dependency between the nodes in the hierarchy. We also provide a strategy to make calls for each node based on the ordering produced by HierLPR, with the intent of controlling FDR or maximizing F-score. The performance of our proposed methods is demonstrated on synthetic datasets as well as a real example of disease diagnosis using NCBI GEO datasets. In these cases, HierLPR shows a favorable result over competing methods in the early part of the precision-recall curve.