 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtreme Learning Machines for Attention-based Multiple Instance Learning in Whole-Slide Image Classification
Mar 13, 2025Whole-slide image classification represents a key challenge in computational pathology and medicine. Attention-based multiple instance learning (MIL) has emerged as an effective approach for this problem. However, the effect of attention mechanism architecture on model performance is not well-documented for biomedical imagery. In this work, we compare different methods and implementations of MIL, including deep learning variants. We introduce a new method using higher-dimensional feature spaces for deep MIL. We also develop a novel algorithm for whole-slide image classification where extreme machine learning is combined with attention-based MIL to improve sensitivity and reduce training complexity. We apply our algorithms to the problem of detecting circulating rare cells (CRCs), such as erythroblasts, in peripheral blood. Our results indicate that nonlinearities play a key role in the classification, as removing them leads to a sharp decrease in stability in addition to a decrease in average area under the curve (AUC) of over 4%. We also demonstrate a considerable increase in robustness of the model with improvements of over 10% in average AUC when higher-dimensional feature spaces are leveraged. In addition, we show that extreme learning machines can offer clear improvements in terms of training efficiency by reducing the number of trained parameters by a factor of 5 whilst still maintaining the average AUC to within 1.5% of the deep MIL model. Finally, we discuss options of enriching the classical computing framework with quantum algorithms in the future. This work can thus help pave the way towards more accurate and efficient single-cell diagnostics, one of the building blocks of precision medicine.
Spatio-temporal transformer to support automatic sign language translation
Feb 04, 2025Sign Language Translation (SLT) systems support hearing-impaired people communication by finding equivalences between signed and spoken languages. This task is however challenging due to multiple sign variations, complexity in language and inherent richness of expressions. Computational approaches have evidenced capabilities to support SLT. Nonetheless, these approaches remain limited to cover gestures variability and support long sequence translations. This paper introduces a Transformer-based architecture that encodes spatio-temporal motion gestures, preserving both local and long-range spatial information through the use of multiple convolutional and attention mechanisms. The proposed approach was validated on the Colombian Sign Language Translation Dataset (CoL-SLTD) outperforming baseline approaches, and achieving a BLEU4 of 46.84%. Additionally, the proposed approach was validated on the RWTH-PHOENIX-Weather-2014T (PHOENIX14T), achieving a BLEU4 score of 30.77%, demonstrating its robustness and effectiveness in handling real-world variations
Distributional loss for convolutional neural network regression and application to GNSS multi-path estimation
Jun 03, 2022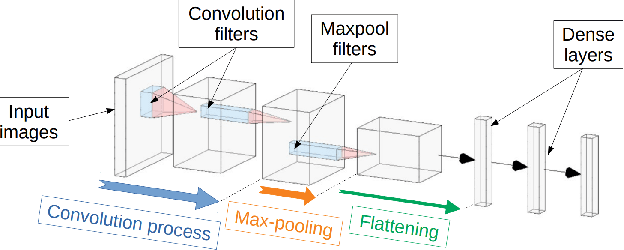

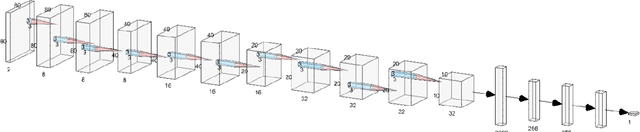

Convolutional Neural Network (CNN) have been widely used in image classification. Over the years, they have also benefited from various enhancements and they are now considered as state of the art techniques for image like data. However, when they are used for regression to estimate some function value from images, fewer recommendations are available. In this study, a novel CNN regression model is proposed. It combines convolutional neural layers to extract high level features representations from images with a soft labelling technique. More specifically, as the deep regression task is challenging, the idea is to account for some uncertainty in the targets that are seen as distributions around their mean. The estimations are carried out by the model in the form of distributions. Building from earlier work, a specific histogram loss function based on the Kullback-Leibler (KL) divergence is applied during training. The model takes advantage of the CNN feature representation and is able to carry out estimation from multi-channel input images. To assess and illustrate the technique, the model is applied to Global Navigation Satellite System (GNSS) multi-path estimation where multi-path signal parameters have to be estimated from correlator output images from the I and Q channels. The multi-path signal delay, magnitude, Doppler shift frequency and phase parameters are estimated from synthetically generated datasets of satellite signals. Experiments are conducted under various receiving conditions and various input images resolutions to test the estimation performances quality and robustness. The results show that the proposed soft labelling CNN technique using distributional loss outperforms classical CNN regression under all conditions. Furthermore, the extra learning performance achieved by the model allows the reduction of input image resolution from 80x80 down to 40x40 or sometimes 20x20.