 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntent-Interest Disentanglement and Item-Aware Intent Contrastive Learning for Sequential Recommendation
Jan 13, 2025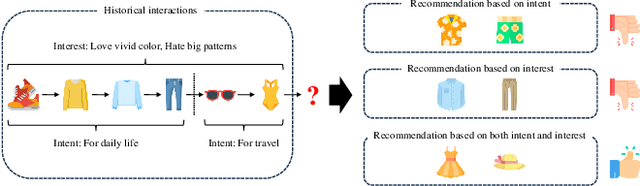
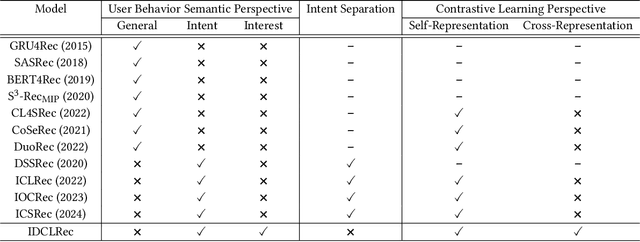


Recommender systems aim to provide personalized item recommendations by capturing user behaviors derived from their interaction history. Considering that user interactions naturally occur sequentially based on users' intents in mind, user behaviors can be interpreted as user intents. Therefore, intent-based sequential recommendations are actively studied recently to model user intents from historical interactions for a more precise user understanding beyond traditional studies that often overlook the underlying semantics behind user interactions. However, existing studies face three challenges: 1) the limited understanding of user behaviors by focusing solely on intents, 2) the lack of robustness in categorizing intents due to arbitrary fixed numbers of intent categories, and 3) the neglect of interacted items in modeling of user intents. To address these challenges, we propose Intent-Interest Disentanglement and Item-Aware Intent Contrastive Learning for Sequential Recommendation (IDCLRec). IDCLRec disentangles user behaviors into intents which are dynamic motivations and interests which are stable tastes of users for a comprehensive understanding of user behaviors. A causal cross-attention mechanism is used to identify consistent interests across interactions, while residual behaviors are modeled as intents by modeling their temporal dynamics through a similarity adjustment loss. In addition, without predefining the number of intent categories, an importance-weighted attention mechanism captures user-specific categorical intent considering the importance of intent for each interaction. Furthermore, we introduce item-aware contrastive learning which aligns intents that occurred the same interaction and aligns intent with item combinations occurred by the corresponding intent. Extensive experiments conducted on real-world datasets demonstrate the effectiveness of IDCLRec.
Cross-channel Recommendation for Multi-channel Retail
Apr 01, 2024An increasing number of brick-and-mortar retailers are expanding their channels to the online domain, transforming them into multi-channel retailers. This transition emphasizes the need for cross-channel recommender systems, aiming to enhance revenue across both offline and online channels. Given that each retail channel represents a separate domain with a unique context, this can be regarded as a cross-domain recommendation (CDR). However, the existing studies on CDR did not address the scenarios where both users and items partially overlap across multi-retail channels which we define as "cross-channel retail recommendation (CCRR)". This paper introduces our original work on CCRR using real-world datasets from a multi-channel retail store. Specifically, (1) we present significant challenges in integrating user preferences across both channels. (2) Accordingly, we propose a novel model for CCRR using a channel-wise attention mechanism to capture different user preferences for the same item on each channel. We empirically validate our model's superiority in addressing CCRR over existing models. (3) Finally, we offer implications for future research on CCRR, delving into our experiment results.
Sequential Recommendation on Temporal Proximities with Contrastive Learning and Self-Attention
Feb 18, 2024



Sequential recommender systems identify user preferences from their past interactions to predict subsequent items optimally. Although traditional deep-learning-based models and modern transformer-based models in previous studies capture unidirectional and bidirectional patterns within user-item interactions, the importance of temporal contexts, such as individual behavioral and societal trend patterns, remains underexplored. Notably, recent models often neglect similarities in users' actions that occur implicitly among users during analogous timeframes-a concept we term vertical temporal proximity. These models primarily adapt the self-attention mechanisms of the transformer to consider the temporal context in individual user actions. Meanwhile, this adaptation still remains limited in considering the horizontal temporal proximity within item interactions, like distinguishing between subsequent item purchases within a week versus a month. To address these gaps, we propose a sequential recommendation model called TemProxRec, which includes contrastive learning and self-attention methods to consider temporal proximities both across and within user-item interactions. The proposed contrastive learning method learns representations of items selected in close temporal periods across different users to be close. Simultaneously, the proposed self-attention mechanism encodes temporal and positional contexts in a user sequence using both absolute and relative embeddings. This way, our TemProxRec accurately predicts the relevant items based on the user-item interactions within a specific timeframe. We validate this work through comprehensive experiments on TemProxRec, consistently outperforming existing models on benchmark datasets as well as showing the significance of considering the vertical and horizontal temporal proximities into sequential recommendation.
A Bi-objective Perspective on Controllable Language Models: Reward Dropout Improves Off-policy Control Performance
Oct 06, 2023



We study the theoretical aspects of CLMs (Controllable Language Models) from a bi-objective optimization perspective. Specifically, we consider the CLMs as an off-policy RL problem that requires simultaneously maximizing the reward and likelihood objectives. Our main contribution consists of three parts. First, we establish the theoretical foundations of CLM by presenting reward upper bound and Pareto improvement/optimality conditions. Second, we analyze conditions that improve and violate Pareto optimality itself, respectively. Finally, we propose Reward Dropout, a simple yet powerful method to guarantee policy improvement based on a Pareto improvement condition. Our theoretical outcomes are supported by not only deductive proofs but also empirical results. The performance of Reward Dropout was evaluated on five CLM benchmark datasets, and it turns out that the Reward Dropout significantly improves the performance of CLMs.
Layer-level activation mechanism
Jul 03, 2023



In this work, we propose a novel activation mechanism aimed at establishing layer-level activation (LayerAct) functions. These functions are designed to be more noise-robust compared to traditional element-level activation functions by reducing the layer-level fluctuation of the activation outputs due to shift in inputs. Moreover, the LayerAct functions achieve a zero-like mean activation output without restricting the activation output space. We present an analysis and experiments demonstrating that LayerAct functions exhibit superior noise-robustness compared to element-level activation functions, and empirically show that these functions have a zero-like mean activation. Experimental results on three benchmark image classification tasks show that LayerAct functions excel in handling noisy image datasets, outperforming element-level activation functions, while the performance on clean datasets is also superior in most cases.