 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping Smart Web-Search Using RegEx
Oct 10, 2021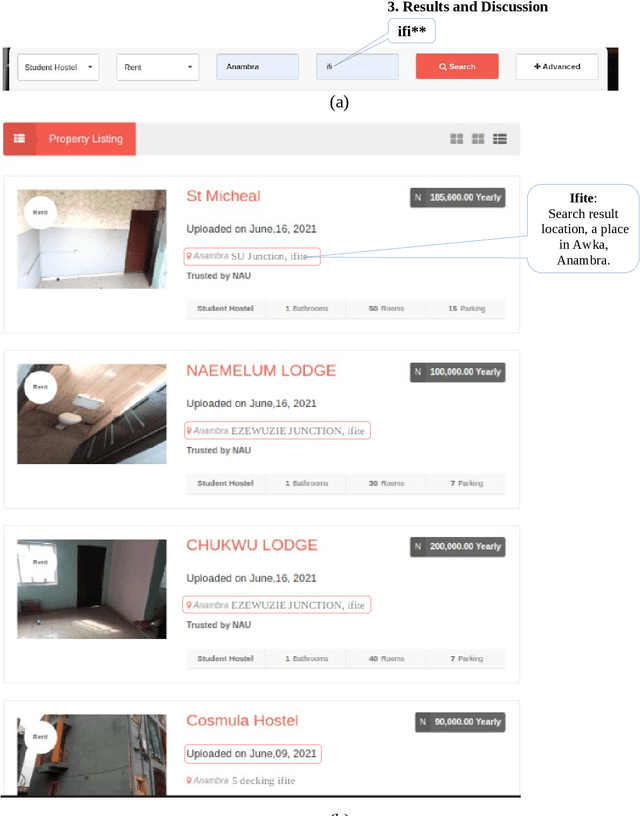
Due to the increasing storage data on Web Applications, it becomes very difficult to use only keyword-based searches to provide comprehensive search results, thus increasing the difficulty for web users to search information on the web. In this paper, we proposed using a combined method of keyword-based and Regular expressions (regEx) searches to perform a search using strings of targeted items for optimal results even as the volume of data around the world on the Internet continues to explode. The idea is to embed regEx patterns as part of the search engine's algorithm in a web application project to provide strings related to the targeted items for more comprehensive coverage of search results. The user's search query is a string of characters guided by search boundaries selected from the entry point. The results returned from the search operation are different results within a category determined by the search boundaries. This is designed to be beneficial to a user who has an obscure idea about the information he/she wanted to search but knows the boundaries within which to get the information. This technique can be applied to data processing tasks such as information extraction and search refinement.
Developing Products Update-Alert System for e-Commerce Websites Users Using HTML Data and Web Scraping Technique
Sep 02, 2021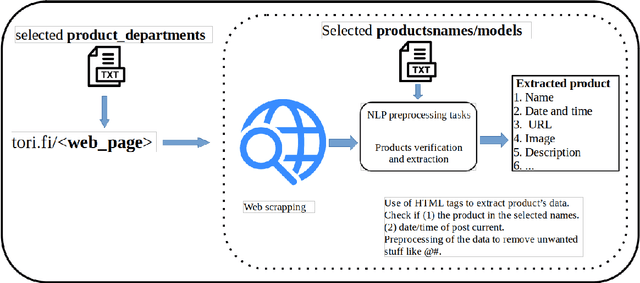

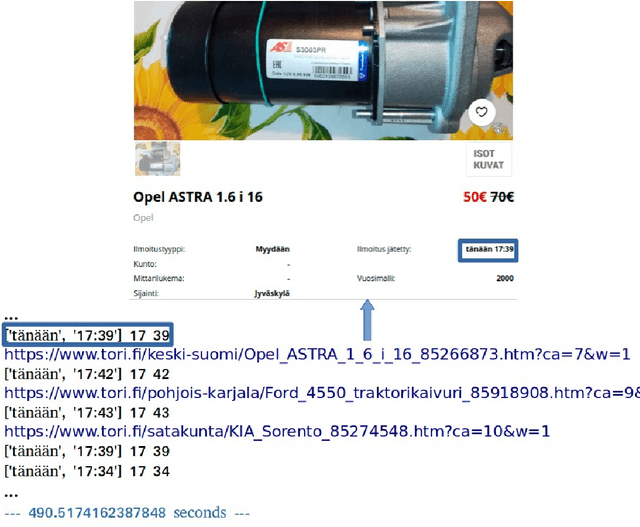
Websites are regarded as domains of limitless information which anyone and everyone can access. The new trend of technology put us to change the way we are doing our business. The Internet now is fastly becoming a new place for business and the advancement in this technology gave rise to the number of e-commerce websites. This made the lifestyle of marketers/vendors, retailers and consumers (collectively regarded as users in this paper) easy, because it provides easy platforms to sale/order items through the internet. This also requires that the users will have to spend a lot of time and effort to search for the best product deals, products updates and offers on e-commerce websites. They have to filter and compare search results by themselves which takes a lot of time and there are chances of ambiguous results. In this paper, we applied web crawling and scraping methods on an e-commerce website to get HTML data for identifying products updates based on the current time. The HTML data is preprocessed to extract details of the products such as name, price, post date and time, etc. to serve as useful information for users.
* 6 pages, 3 figures, 1 table, IJNLC Journal