 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast Landmark Localization with 3D Component Reconstruction and CNN for Cross-Pose Recognition
Aug 31, 2017
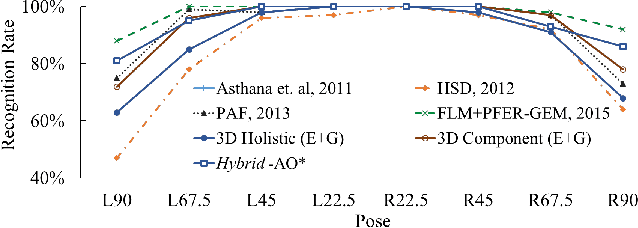
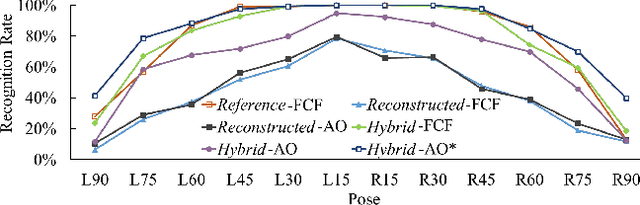

Two approaches are proposed for cross-pose face recognition, one is based on the 3D reconstruction of facial components and the other is based on the deep Convolutional Neural Network (CNN). Unlike most 3D approaches that consider holistic faces, the proposed approach considers 3D facial components. It segments a 2D gallery face into components, reconstructs the 3D surface for each component, and recognizes a probe face by component features. The segmentation is based on the landmarks located by a hierarchical algorithm that combines the Faster R-CNN for face detection and the Reduced Tree Structured Model for landmark localization. The core part of the CNN-based approach is a revised VGG network. We study the performances with different settings on the training set, including the synthesized data from 3D reconstruction, the real-life data from an in-the-wild database, and both types of data combined. We investigate the performances of the network when it is employed as a classifier or designed as a feature extractor. The two recognition approaches and the fast landmark localization are evaluated in extensive experiments, and compared to stateof-the-art methods to demonstrate their efficacy.