 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTCMM: Token Constraint and Multi-Scale Memory Bank of Contrastive Learning for Unsupervised Person Re-identification
Jan 15, 2025
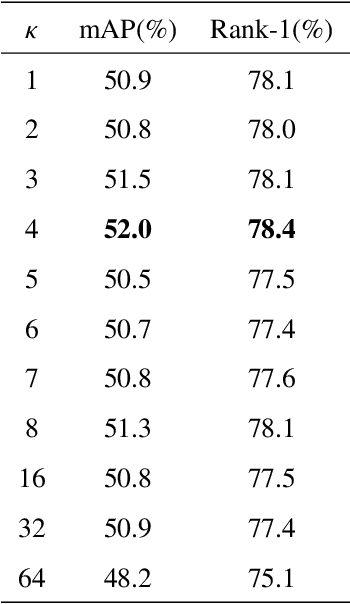
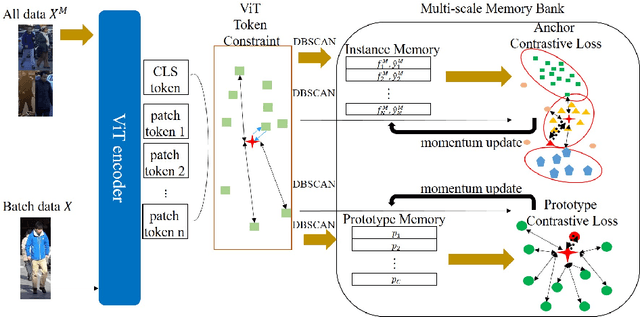

This paper proposes the ViT Token Constraint and Multi-scale Memory bank (TCMM) method to address the patch noises and feature inconsistency in unsupervised person re-identification works. Many excellent methods use ViT features to obtain pseudo labels and clustering prototypes, then train the model with contrastive learning. However, ViT processes images by performing patch embedding, which inevitably introduces noise in patches and may compromise the performance of the re-identification model. On the other hand, previous memory bank based contrastive methods may lead data inconsistency due to the limitation of batch size. Furthermore, existing pseudo label methods often discard outlier samples that are difficult to cluster. It sacrifices the potential value of outlier samples, leading to limited model diversity and robustness. This paper introduces the ViT Token Constraint to mitigate the damage caused by patch noises to the ViT architecture. The proposed Multi-scale Memory enhances the exploration of outlier samples and maintains feature consistency. Experimental results demonstrate that our system achieves state-of-the-art performance on common benchmarks. The project is available at \href{https://github.com/andy412510/TCMM}{https://github.com/andy412510/TCMM}.
ReST: A Reconfigurable Spatial-Temporal Graph Model for Multi-Camera Multi-Object Tracking
Aug 25, 2023Multi-Camera Multi-Object Tracking (MC-MOT) utilizes information from multiple views to better handle problems with occlusion and crowded scenes. Recently, the use of graph-based approaches to solve tracking problems has become very popular. However, many current graph-based methods do not effectively utilize information regarding spatial and temporal consistency. Instead, they rely on single-camera trackers as input, which are prone to fragmentation and ID switch errors. In this paper, we propose a novel reconfigurable graph model that first associates all detected objects across cameras spatially before reconfiguring it into a temporal graph for Temporal Association. This two-stage association approach enables us to extract robust spatial and temporal-aware features and address the problem with fragmented tracklets. Furthermore, our model is designed for online tracking, making it suitable for real-world applications. Experimental results show that the proposed graph model is able to extract more discriminating features for object tracking, and our model achieves state-of-the-art performance on several public datasets.