 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSLIC: Secure Learned Image Codec through Compressed Domain Watermarking to Defend Image Manipulation
Oct 19, 2024



The digital image manipulation and advancements in Generative AI, such as Deepfake, has raised significant concerns regarding the authenticity of images shared on social media. Traditional image forensic techniques, while helpful, are often passive and insufficient against sophisticated tampering methods. This paper introduces the Secure Learned Image Codec (SLIC), a novel active approach to ensuring image authenticity through watermark embedding in the compressed domain. SLIC leverages neural network-based compression to embed watermarks as adversarial perturbations in the latent space, creating images that degrade in quality upon re-compression if tampered with. This degradation acts as a defense mechanism against unauthorized modifications. Our method involves fine-tuning a neural encoder/decoder to balance watermark invisibility with robustness, ensuring minimal quality loss for non-watermarked images. Experimental results demonstrate SLIC's effectiveness in generating visible artifacts in tampered images, thereby preventing their redistribution. This work represents a significant step toward developing secure image codecs that can be widely adopted to safeguard digital image integrity.
Exploring Compressed Image Representation as a Perceptual Proxy: A Study
Jan 14, 2024We propose an end-to-end learned image compression codec wherein the analysis transform is jointly trained with an object classification task. This study affirms that the compressed latent representation can predict human perceptual distance judgments with an accuracy comparable to a custom-tailored DNN-based quality metric. We further investigate various neural encoders and demonstrate the effectiveness of employing the analysis transform as a perceptual loss network for image tasks beyond quality judgments. Our experiments show that the off-the-shelf neural encoder proves proficient in perceptual modeling without needing an additional VGG network. We expect this research to serve as a valuable reference developing of a semantic-aware and coding-efficient neural encoder.
Image Data Hiding in Neural Compressed Latent Representations
Oct 01, 2023



We propose an end-to-end learned image data hiding framework that embeds and extracts secrets in the latent representations of a generic neural compressor. By leveraging a perceptual loss function in conjunction with our proposed message encoder and decoder, our approach simultaneously achieves high image quality and high bit accuracy. Compared to existing techniques, our framework offers superior image secrecy and competitive watermarking robustness in the compressed domain while accelerating the embedding speed by over 50 times. These results demonstrate the potential of combining data hiding techniques and neural compression and offer new insights into developing neural compression techniques and their applications.
CPIPS: Learning to Preserve Perceptual Distances in End-to-End Image Compression
Oct 01, 2023



Lossy image coding standards such as JPEG and MPEG have successfully achieved high compression rates for human consumption of multimedia data. However, with the increasing prevalence of IoT devices, drones, and self-driving cars, machines rather than humans are processing a greater portion of captured visual content. Consequently, it is crucial to pursue an efficient compressed representation that caters not only to human vision but also to image processing and machine vision tasks. Drawing inspiration from the efficient coding hypothesis in biological systems and the modeling of the sensory cortex in neural science, we repurpose the compressed latent representation to prioritize semantic relevance while preserving perceptual distance. Our proposed method, Compressed Perceptual Image Patch Similarity (CPIPS), can be derived at a minimal cost from a learned neural codec and computed significantly faster than DNN-based perceptual metrics such as LPIPS and DISTS.
Multi-task deep CNN model for no-reference image quality assessment on smartphone camera photos
Aug 27, 2020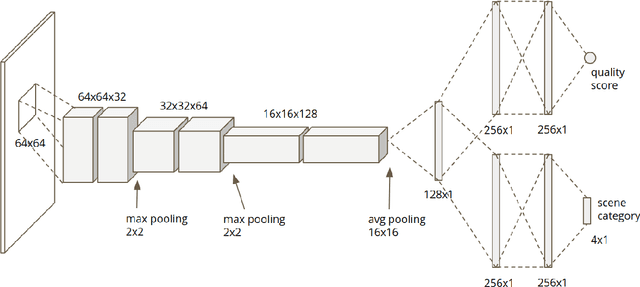
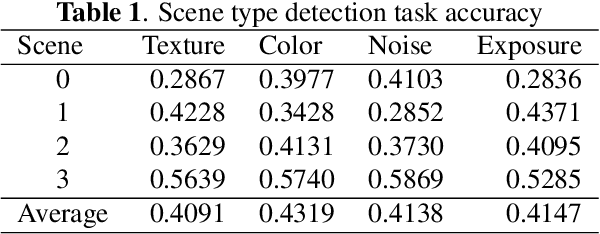
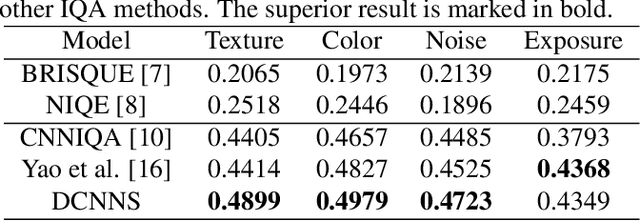
Smartphone is the most successful consumer electronic product in today's mobile social network era. The smartphone camera quality and its image post-processing capability is the dominant factor that impacts consumer's buying decision. However, the quality evaluation of photos taken from smartphones remains a labor-intensive work and relies on professional photographers and experts. As an extension of the prior CNN-based NR-IQA approach, we propose a multi-task deep CNN model with scene type detection as an auxiliary task. With the shared model parameters in the convolution layer, the learned feature maps could become more scene-relevant and enhance the performance. The evaluation result shows improved SROCC performance compared to traditional NR-IQA methods and single task CNN-based models.