 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRingCNN: Exploiting Algebraically-Sparse Ring Tensors for Energy-Efficient CNN-Based Computational Imaging
Apr 19, 2021



In the era of artificial intelligence, convolutional neural networks (CNNs) are emerging as a powerful technique for computational imaging. They have shown superior quality for reconstructing fine textures from badly-distorted images and have potential to bring next-generation cameras and displays to our daily life. However, CNNs demand intensive computing power for generating high-resolution videos and defy conventional sparsity techniques when rendering dense details. Therefore, finding new possibilities in regular sparsity is crucial to enable large-scale deployment of CNN-based computational imaging. In this paper, we consider a fundamental but yet well-explored approach -- algebraic sparsity -- for energy-efficient CNN acceleration. We propose to build CNN models based on ring algebra that defines multiplication, addition, and non-linearity for n-tuples properly. Then the essential sparsity will immediately follow, e.g. n-times reduction for the number of real-valued weights. We define and unify several variants of ring algebras into a modeling framework, RingCNN, and make comparisons in terms of image quality and hardware complexity. On top of that, we further devise a novel ring algebra which minimizes complexity with component-wise product and achieves the best quality using directional ReLU. Finally, we implement an accelerator, eRingCNN, in two settings, n=2 and 4 (50% and 75% sparsity), with 40 nm technology to support advanced denoising and super-resolution at up to 4K UHD 30 fps. Layout results show that they can deliver equivalent 41 TOPS using 3.76 W and 2.22 W, respectively. Compared to the real-valued counterpart, our ring convolution engines for n=2 achieve 2.00x energy efficiency and 2.08x area efficiency with similar or even better image quality. With n=4, the efficiency gains of energy and area are further increased to 3.84x and 3.77x with 0.11 dB drop of PSNR.
ERNet Family: Hardware-Oriented CNN Models for Computational Imaging Using Block-Based Inference
Oct 13, 2019

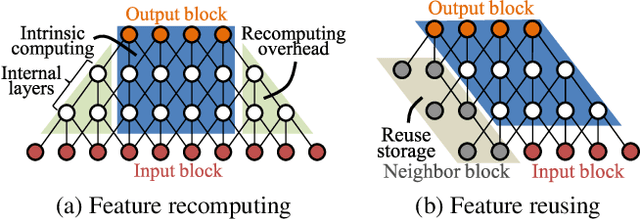

Convolutional neural networks (CNNs) demand huge DRAM bandwidth for computational imaging tasks, and block-based processing has recently been applied to greatly reduce the bandwidth. However, the induced additional computation for feature recomputing or the large SRAM for feature reusing will degrade the performance or even forbid the usage of state-of-the-art models. In this paper, we address these issues by considering the overheads and hardware constraints in advance when constructing CNNs. We investigate a novel model family---ERNet---which includes temporary layer expansion as another means for increasing model capacity. We analyze three ERNet variants in terms of hardware requirement and introduce a hardware-aware model optimization procedure. Evaluations on Full HD and 4K UHD applications will be given to show the effectiveness in terms of image quality, pixel throughput, and SRAM usage. The results also show that, for block-based inference, ERNet can outperform the state-of-the-art FFDNet and EDSR-baseline models for image denoising and super-resolution respectively.
eCNN: A Block-Based and Highly-Parallel CNN Accelerator for Edge Inference
Oct 13, 2019


Convolutional neural networks (CNNs) have recently demonstrated superior quality for computational imaging applications. Therefore, they have great potential to revolutionize the image pipelines on cameras and displays. However, it is difficult for conventional CNN accelerators to support ultra-high-resolution videos at the edge due to their considerable DRAM bandwidth and power consumption. Therefore, finding a further memory- and computation-efficient microarchitecture is crucial to speed up this coming revolution. In this paper, we approach this goal by considering the inference flow, network model, instruction set, and processor design jointly to optimize hardware performance and image quality. We apply a block-based inference flow which can eliminate all the DRAM bandwidth for feature maps and accordingly propose a hardware-oriented network model, ERNet, to optimize image quality based on hardware constraints. Then we devise a coarse-grained instruction set architecture, FBISA, to support power-hungry convolution by massive parallelism. Finally,we implement an embedded processor---eCNN---which accommodates to ERNet and FBISA with a flexible processing architecture. Layout results show that it can support high-quality ERNets for super-resolution and denoising at up to 4K Ultra-HD 30 fps while using only DDR-400 and consuming 6.94W on average. By comparison, the state-of-the-art Diffy uses dual-channel DDR3-2133 and consumes 54.3W to support lower-quality VDSR at Full HD 30 fps. Lastly, we will also present application examples of high-performance style transfer and object recognition to demonstrate the flexibility of eCNN.